【 Python 入門】CSVファイルを操作する方法を徹底解説!Pandasの使い方も合わせて紹介!

Python を使った CSV ファイルの操作は、データ分析において非常に重要です。本記事では、 CSV ファイル作成から操作方法までを詳しく解説します。
実行環境
- Google Colaboratory
- Python: 3.10.12
- Windows11
目次
Python の csv モジュールの基本的な使い方
Python には標準ライブラリとして csv があり、これを使うことで簡単に CSV ファイルを読み書きできます。 CSV ファイルは、カンマ(,)で区切られた非常にシンプルな構造のテキストファイルです。
まずは CSV ファイルを作成しましょう。以下のデータは、 Sample High School ( S 高校)の体力測定結果を記録した架空のデータです。下記のデータを「メモ帳」にコピーして「 sample.csv 」という名前で保存してください。後に参考画像を載せます。
ID,Name,50m Run (seconds),Throwing Distance (m),Side Steps (reps/20s) 1,Taro Yamada,7.5,45,50 2,Hanako Sato,8.2,38,48 3,Ichiro Suzuki,7.8,50,52 4,Misaki Tanaka,8.0,42,47 5,Kenta Takahashi,7.3,48,53 6,Mao Ito,8.1,40,49 7,Yuko Watanabe,7.9,44,51 8,Ryo Nakamura,7.6,46,50 9,Ai Kobayashi,8.3,39,46 10,Daisuke Kato,7.4,47,52
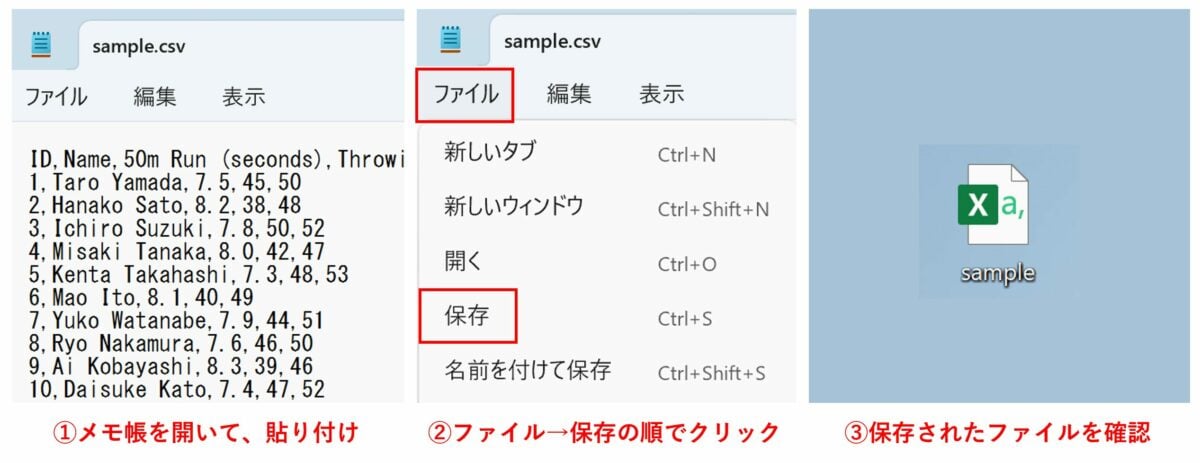
CSV 形式のデータは、テキストエディタやスプレッドシートソフト(例: Excel )で簡単に内容を確認・編集できます。例えば、作成したファイルを Excel で開くと次のように表示されます。
データの列(カラム)は以下の通りです。
ID 個別番号
Name 名前
50m Run (seconds) 50 m走(秒)
Throwing Distance (m) 遠投( m )
Side Steps (reps/20s) 反復横跳び(回/ 20 秒)
ID | Name | 50m Run (seconds) | Throwing Distance (m) | Side Steps (reps/20s) |
|---|---|---|---|---|
1 | Taro Yamada | 7.5 | 45 | 50 |
2 | Hanako Sato | 8.2 | 38 | 48 |
3 | Ichiro Suzuki | 7.8 | 50 | 52 |
4 | Misaki Tanaka | 8.0 | 42 | 47 |
5 | Kenta Takahashi | 7.3 | 48 | 53 |
6 | Mao Ito | 8.1 | 40 | 49 |
7 | Yuko Watanabe | 7.9 | 44 | 51 |
8 | Ryo Nakamura | 7.6 | 46 | 50 |
9 | Ai Kobayashi | 8.3 | 39 | 46 |
10 | Daisuke Kato | 7.4 | 47 | 52 |
sample.csv
CSV ファイルの読み込み
次に、CSV ファイルを読み込む基本的な方法を紹介します。以下のコードでは、先程作成した sample.csv ファイルを読み込み、各行のデータをリストとして表示します。
# csv モジュールをインポート import csv # sample.csv を読み込む with open('sample.csv') as file: reader = csv.reader(file) for row in reader: print(row)
コード解説
- with open 文を使ってファイルを開きます。
- csv.reader を使ってCSVファイルを行ごとに読み込み、for 文で各行を出力します。
以下の記事では、 for 文を詳しく紹介しています。併せてご覧ください!
.png&w=3840&q=75)
['ID', 'Name', '50m Run (seconds)', 'Throwing Distance (m)', 'Side Steps (reps/20s)'] ['1', 'Taro Yamada', '7.5', '45', '50'] ['2', 'Hanako Sato', '8.2', '38', '48'] ['3', 'Ichiro Suzuki', '7.8', '50', '52'] ['4', 'Misaki Tanaka', '8.0', '42', '47'] ['5', 'Kenta Takahashi', '7.3', '48', '53'] ['6', 'Mao Ito', '8.1', '40', '49'] ['7', 'Yuko Watanabe', '7.9', '44', '51'] ['8', 'Ryo Nakamura', '7.6', '46', '50'] ['9', 'Ai Kobayashi', '8.3', '39', '46'] ['10', 'Daisuke Kato', '7.4', '47', '52']
このように、 CSV ファイルの各行をリストとして取得できます。
CSVファイルへの書き込み
新しくCSVファイルを作成する
次に、 CSV ファイルにリスト形式のデータを書き込む方法を紹介します。ここでは、 with open() 内に ファイルを開くモード 'W' (記述モード)を追加します。学生の名前、年齢、身長、体重といった基礎情報が入るので、ファイル名は「base.csv」とします。
# CSV ファイルにデータを書き込む data = [ ['ID', 'Name', 'Age', 'Height', 'Weight'], [1, 'Taro Yamada', 16, 170, 65], [2, 'Hanako Sato', 16, 160, 55], [3, 'Ichiro Suzuki', 17, 175, 68], [4, 'Misaki Tanaka', 16, 162, 54], [5, 'Kenta Takahashi', 17, 178, 70], [6, 'Mao Ito', 16, 165, 57], [7, 'Yuko Watanabe', 16, 168, 60], [8, 'Ryo Nakamura', 17, 172, 66], [9, 'Ai Kobayashi', 16, 158, 52], [10, 'Daisuke Kato', 16, 176, 69], ] with open('base.csv', 'w') as csvfile: # 'w'モードで開く writer = csv.writer(csvfile) writer.writerows(data)
保存された CSV ファイルを確認します。
以下のデータが作成できました。
ID 個別番号
Name 名前
Age 年齢
Height 身長
Weight 体重
ID | Name | Age | Height | Weight |
|---|---|---|---|---|
1 | Taro Yamada | 16 | 170 | 65 |
--以下省略-- | --以下省略-- | --以下省略-- | --以下省略-- | --以下省略-- |
base.csv
既存の CSV ファイルにデータを追記する
すでに存在する CSV ファイルにデータを追加したい場合は、ファイルを開くモードを 'a' (追記モード)に変更する必要があります。ここでは新たに 2 名の学生のデータを追加します。
# 追加するデータ new_data = [ ['11','Kenji Yamamoto', '7.7', '43', '49'], ['12','Yumi Nakamoto', '8.0', '41', '47'] ] # 'sample.csv'ファイルにデータを追加する with open('sample.csv', 'a', newline='') as csvfile: # 'a'モードで開く writer = csv.writer(csvfile) writer.writerows(new_data) # 新しいデータを追加
コード解説
- newline='' は、書き込み時に余分な改行を防ぐために使用します。
ID | Name | 50m Run (seconds) | Throwing Distance (m) | Side Steps (reps/20s) |
|---|---|---|---|---|
10 | Daisuke Kato | 7.4 | 47 | 52 |
11 | Kenji Yamamoto | 7.7 | 43 | 49 |
12 | Yumi Nakamoto | 8.0 | 41 | 47 |
sample.csv
保存された CSV ファイル (sample.csv) を開くと、2 行追加されていることが確認できます。
base.csv も同じように追加しましょう。
# 追加するデータ new_data = [ [11, 'Kenji Yamamoto', 16, 174, 67.3], [12, 'Yumi Nakamoto', 16, 163, 56.4], ] # 'base.csv'ファイルにデータを追加する with open('base.csv', 'a', newline='') as csvfile: # 'a'モードで開く writer = csv.writer(csvfile) writer.writerows(new_data) # 新しいデータを追加
ID | Name | Age | Height | Weight |
|---|---|---|---|---|
10 | Daisuke Kato | 16 | 176 | 69 |
11 | Kenji Yamamoto | 7.7 | 43 | 49 |
12 | Yumi Nakamoto | 8.0 | 41 | 47 |
base.csv
データの整形とフィルタリング
次に、CSV ファイルから読み込んだデータを整形したり、特定の条件に基づいてフィルタリングする方法を紹介します。
先程は、 csv でCSVファイルを操作する方法をご紹介しましたが、データの整形や分析には、 pandas ライブラリを使うと便利です。
pandas でデータを操作する方法は、こちらの記事をご覧ください。

データの結合
以下のコードでは、先程作成した「 sample.csv 」と「 base.csv 」を、pandas を用いてデータ内の ID と Name で照合し、 1 つの CSV ファイルにまとめます。
# pandas をインポート import pandas as pd # ファイル 1 : 体力測定結果のデータ (sample.csv) を読み込む df_sample = pd.read_csv('sample.csv') # ファイル 2 : 身長と体重のデータ (base.csv) を読み込む df_base = pd.read_csv('base.csv') # ID と名前でデータをマージする df_merged = pd.merge(df_sample, df_base, on=['ID', 'Name']) # 結果を表示する print(df_merged) # マージされたデータを新しいCSVに保存 df_merged.to_csv('base_sample.csv', index=False)
コード解説
- pd.merge は 2 つのデータセットを 1 つにまとめます。
- index=False は、データフレームのインデックス(行番号)を CSV ファイルに含めません。
ID | Name | 50m Run (seconds) | Throwing Distance (m) | Side Steps (reps/20s) | Age | Height | Weight |
|---|---|---|---|---|---|---|---|
1 | Taro Yamada | 7.5 | 45 | 50 | 16 | 170 | 65.0 |
2 | Hanako Sato | 8.2 | 38 | 48 | 16 | 160 | 55.0 |
3 | Ichiro Suzuki | 7.8 | 50 | 52 | 17 | 175 | 68.0 |
4 | Misaki Tanaka | 8.0 | 42 | 47 | 16 | 162 | 54.0 |
5 | Kenta Takahashi | 7.3 | 48 | 53 | 17 | 178 | 70.0 |
6 | Mao Ito | 8.1 | 40 | 49 | 16 | 165 | 57.0 |
7 | Yuko Watanabe | 7.9 | 44 | 51 | 16 | 168 | 60.0 |
8 | Ryo Nakamura | 7.6 | 46 | 50 | 17 | 172 | 66.0 |
9 | Ai Kobayashi | 8.3 | 39 | 46 | 16 | 158 | 52.0 |
10 | Daisuke Kato | 7.4 | 47 | 52 | 16 | 176 | 69.0 |
11 | Kenji Yamamoto | 7.7 | 43 | 49 | 16 | 174 | 67.3 |
12 | Yumi Nakamoto | 8.0 | 41 | 47 | 16 | 163 | 56.4 |
base_sample.csv
保存された CSV(base_sample.csv) を確認して、上記のように出力されれば完璧です!
条件に基づいたデータのフィルタリング
次に、条件に基づいてデータをフィルタリングする方法を紹介します。例えば、 50 m走を 7.5 秒以内に走る学生のデータを抽出するには比較演算子を使用します。複数条件の設定もできます。ここでは、既に読み込み済の変数「 df_merged 」を使用します。
# 50 m走が 7.5 秒以内の学生を表示する。 filtered_df1 = df_merged[df_merged['50m Run (seconds)'] <= 7.5] print(filtered_df1) # 複数条件でのフィルタリング filtered_df2 = df_merged[(df_merged['50m Run (seconds)'] <= 7.5) & (df_['Weight'] == '70')] print(filtered_df2)
ID Name 50m Run (seconds) Throwing Distance (m) \ 0 1 Taro Yamada 7.5 45 4 5 Kenta Takahashi 7.3 48 9 10 Daisuke Kato 7.4 47 Side Steps (reps/20s) Age Height Weight 0 50 16 170 65.0 4 53 17 178 70.0 9 52 16 176 69.0
ID Name 50m Run (seconds) Throwing Distance (m) \ 4 5 Kenta Takahashi 7.3 48 Side Steps (reps/20s) Age Height Weight 4 53 17 178 70.0
比較演算子は、こちらの記事が参考になります。

データの集計と分析
続けて、 CSV ファイルのデータを集計・分析する方法も確認します。
列の平均や合計の計算
データの合計や平均を計算する場合も pandas が役立ちます。平均を求めるには mean を、合計を求めるには sum を使用します。
# 50 m走の平均タイムを計算 average_age = df_merged['50m Run (seconds)'].mean() # 50 m走の全体合計タイムを計算 total_age = df_merged['50m Run (seconds)'].sum() print(f'Average Age: {average_age},Total Age: {total_age} ')
Average Age: 7.816666666666667,Total Age: 93.80000000000001
平均タイムはおよそ 7.8 秒、 1 人ずつ計測して全員が走り終わるまでにおよそ 93.8 秒かかります。
データの基本統計量の算出
データの基本統計量(平均、中央値、最小値、最大値など)は、 describe を使用して簡単に算出できます。
# 数値データの基本統計量を算出 stats = df_merged.describe() print(stats)
ID 50m Run (seconds) Throwing Distance (m) \ count 12.000000 12.000000 12.000000 mean 6.500000 7.816667 43.583333 std 3.605551 0.321455 3.752777 min 1.000000 7.300000 38.000000 25% 3.750000 7.575000 40.750000 50% 6.500000 7.850000 43.500000 75% 9.250000 8.025000 46.250000 max 12.000000 8.300000 50.000000 Side Steps (reps/20s) Age Height Weight count 12.000000 12.000000 12.000000 12.000000 mean 49.500000 16.250000 168.416667 61.583333 std 2.236068 0.452267 6.748176 6.570711 min 46.000000 16.000000 158.000000 52.000000 25% 47.750000 16.000000 162.750000 55.750000 50% 49.500000 16.000000 169.000000 62.500000 75% 51.250000 16.250000 174.250000 67.250000 max 53.000000 17.000000 178.000000 70.000000
補足
count 列に含まれるデータの数
mean 列の平均値
std 標準偏差
min 最小値
max 最大値
カテゴリーデータは、その列に含まれるデータの頻度や種類を describe(include=['O']) で確認できます。 describe(include=['all']) で数値データとカテゴリーデータを同時に表示もできます。
# カテゴリーデータの確認 stats = df_merged.describe(include=['O']) print(stats)
Name count 12 unique 12 top Taro Yamada freq 1
補足
count 列に含まれるデータの数
unique 列に含まれるデータの種類
top 列の中で最も数の多い unique
freq top の数
データの可視化による傾向の把握
データを視覚的に理解するためには、グラフ化が有効です。ここでは、 matplotlib を使ってデータを可視化する方法を紹介します。
ヒストグラムの作成
まずは 、 matplotlib を使えるようにインポートして、身長をヒストグラムで表現します。
# matplotlib をインポート import matplotlib.pyplot as plt # ヒストグラムの作成 plt.hist(df_merged['Height'], bins=10, color='skyblue', edgecolor='black') plt.title('Height Distribaution') plt.xlabel('Height (cm)') plt.ylabel('Frequency') plt.show()
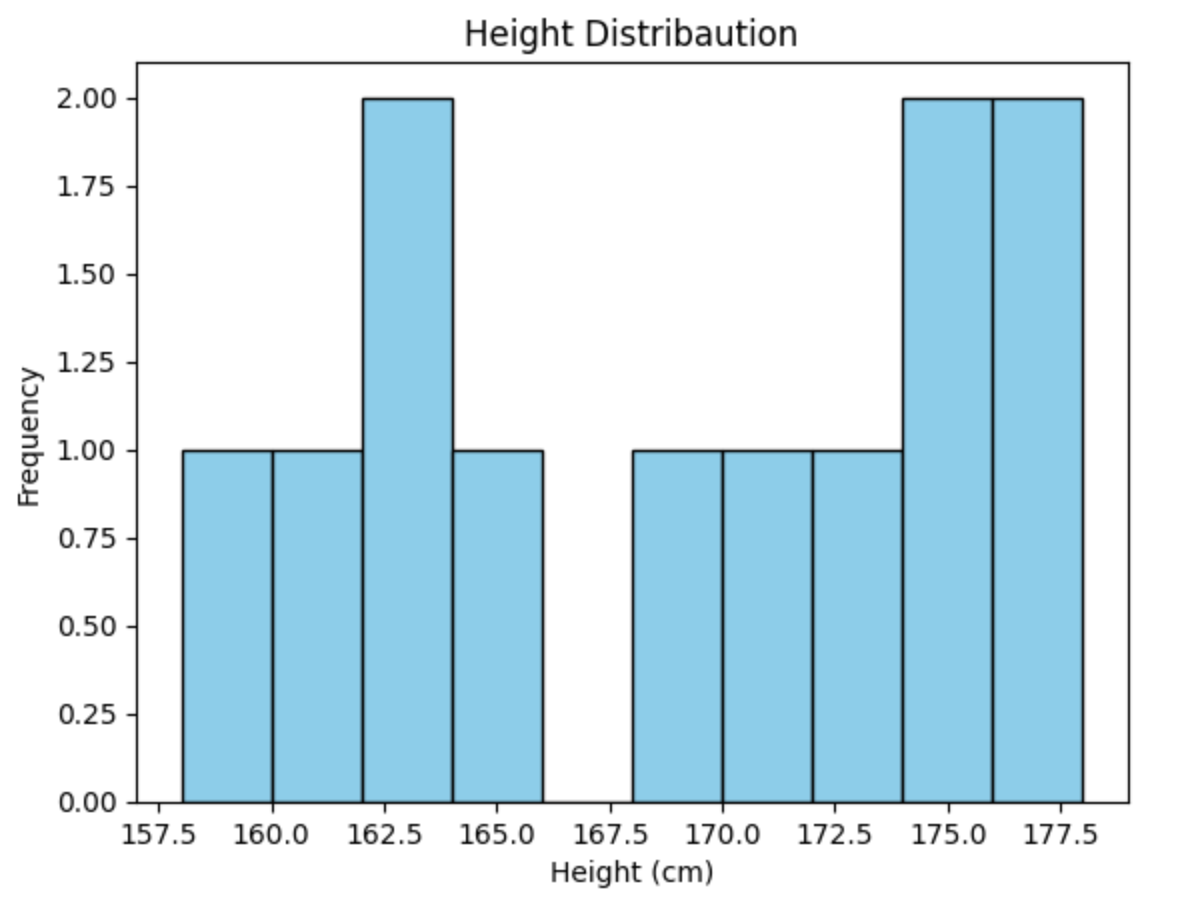
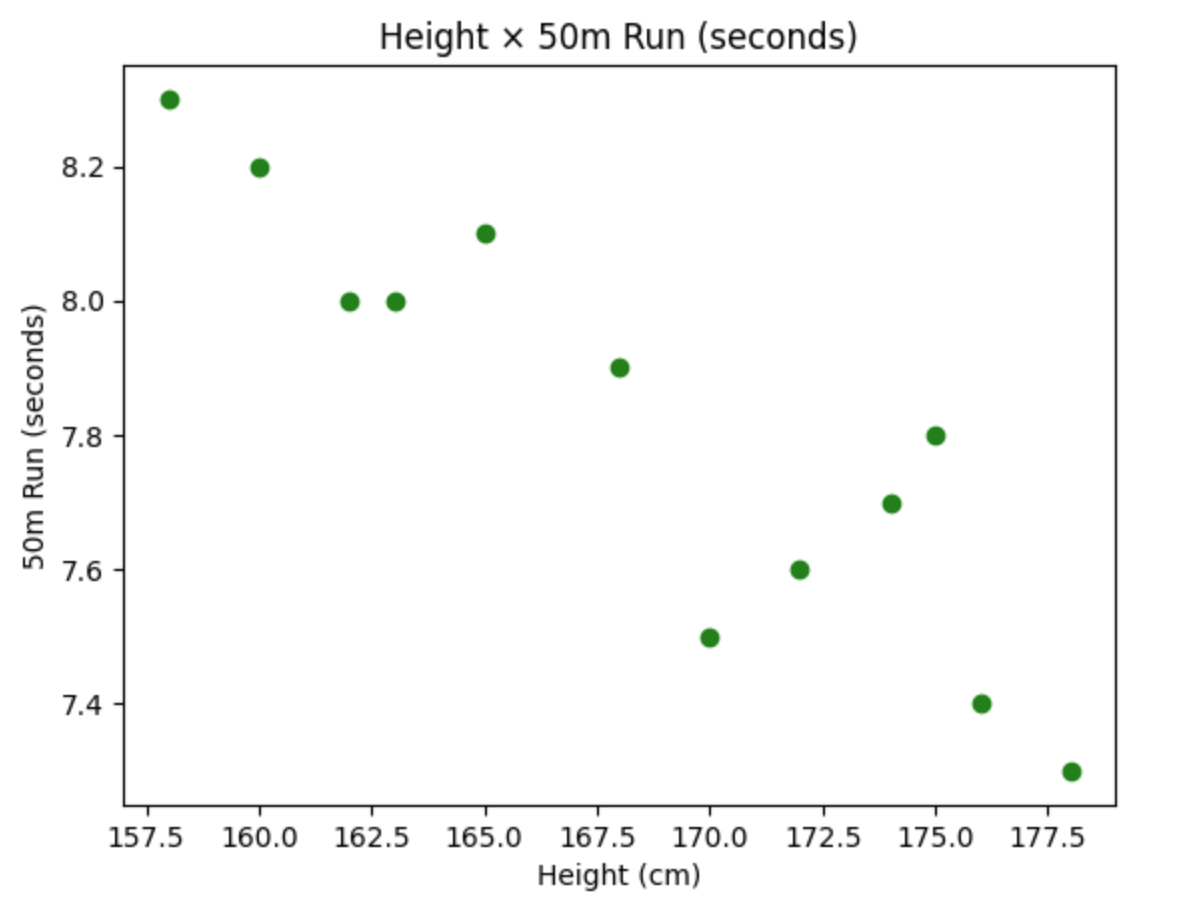
散布図の作成
次に、身長と 50 m走の 2 つの変数間の関係を散布図で表現します。
# 散布図の作成 plt.scatter(df_merged['Height'], df_merged['50m Run (seconds)'], color='green') plt.title('Height × 50m Run (seconds)') plt.xlabel('Height (cm)') plt.ylabel('50m Run (seconds)') plt.show()
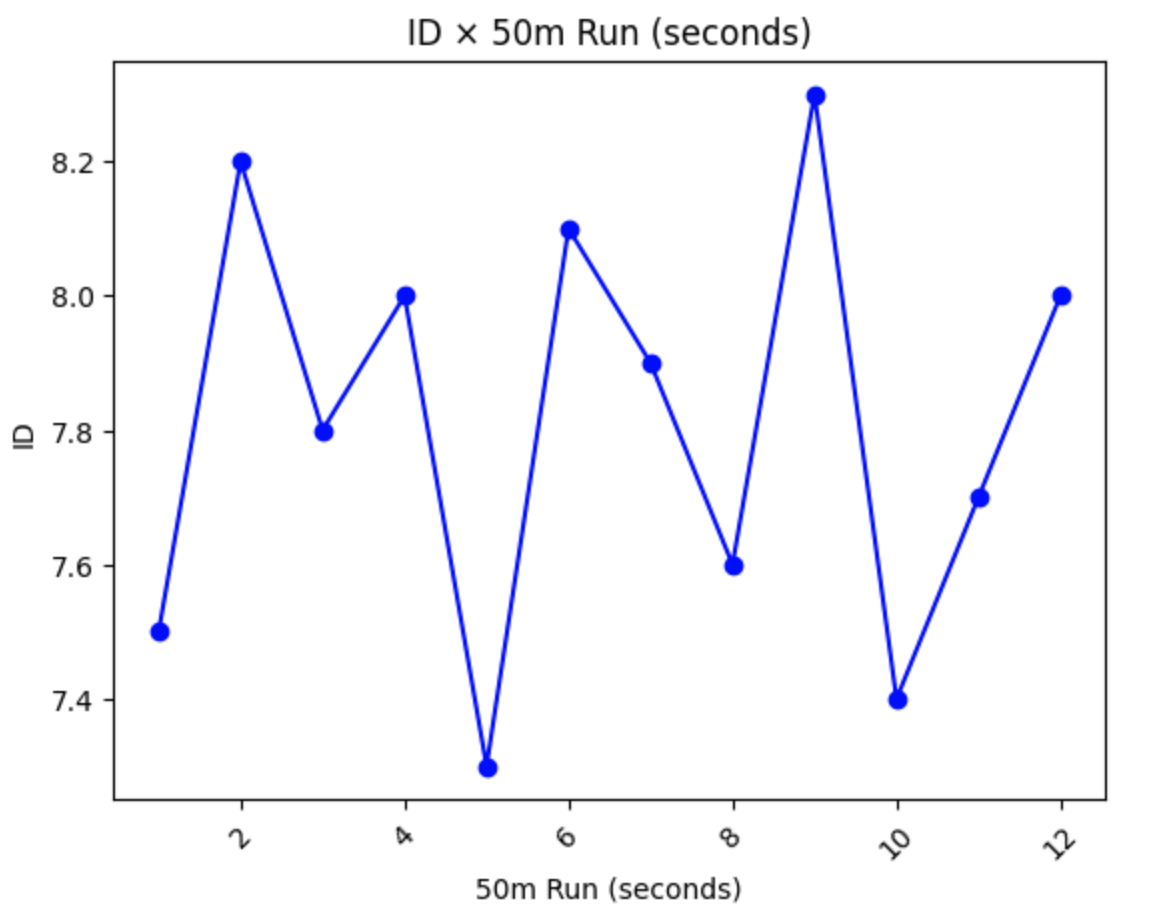
データの折れ線グラフや棒グラフの描画
データの変化を折れ線グラフや棒グラフで表現もできます。
# 折れ線グラフの作成 plt.plot(df_merged['ID'], df_merged['50m Run (seconds)'], marker='o', linestyle='-', color='blue') plt.title('ID × 50m Run (seconds)') plt.xlabel('50m Run (seconds)') plt.ylabel('ID') plt.xticks(rotation=45) plt.show()
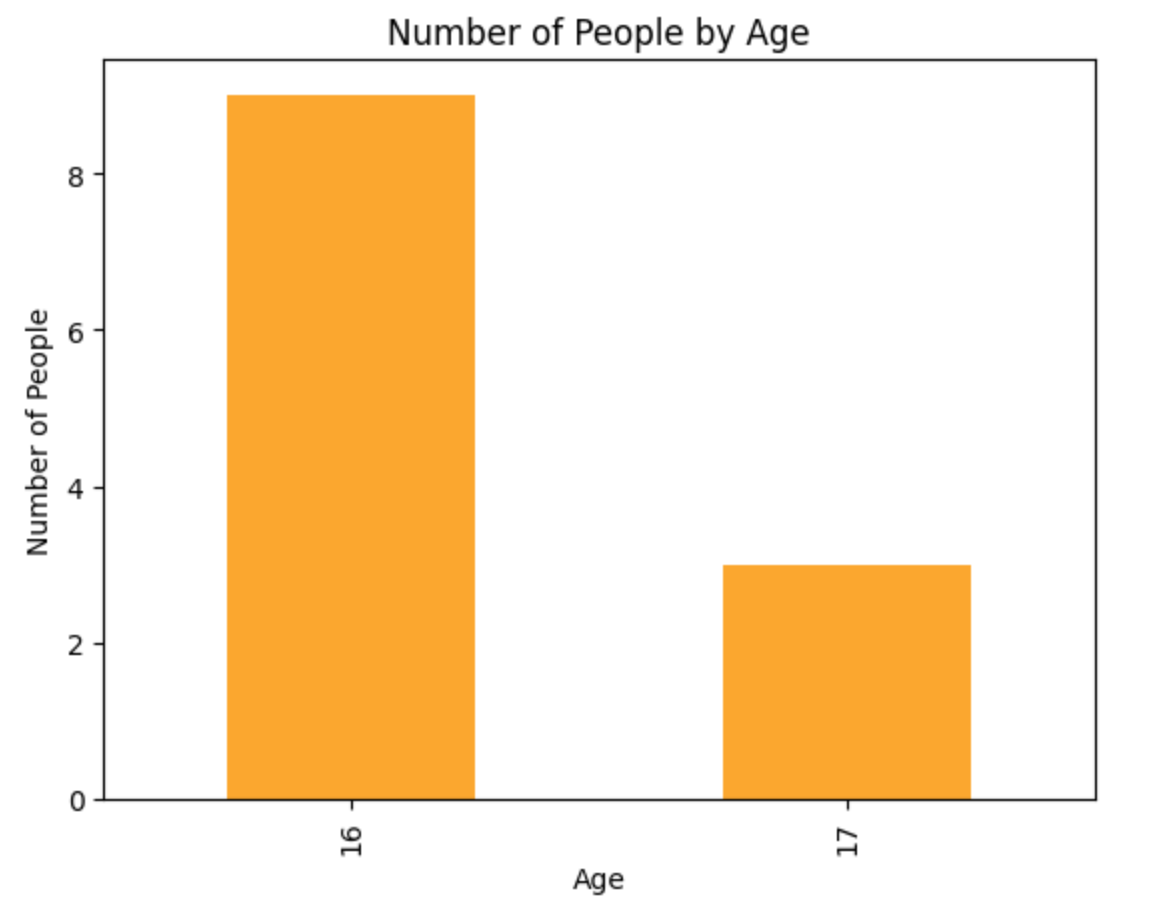
# 年齢をカウントして棒グラフを作成 df_merged['Age'].value_counts().plot(kind='bar', color='orange') plt.title('Number of People by Age') plt.xlabel('Age') plt.ylabel('Number of People') plt.show()
「もっと、かっこいいグラフが書きたい!」と思った方は、以下の記事も併せてご覧ください。

CSV ファイルを Excel に変換する方法
最後に、 CSV ファイルを Excel に変換する方法を紹介します。
# CSV を読み込み df = pd.read_csv('sample.csv') # エクセルファイルに書き込み df.to_excel('output.xlsx', index=False)
コード解説
to_excel 関数を使用して、データフレームを Excel 形式に変換して書き出すことができます。
以下のようにして、これまで扱ってきたデータを Excel ファイルに書き込むこともできます。
# エクセルファイルに書き込み df_merged.to_excel('merged.xlsx', index=False)
Python で Excel を操作する方法を詳しく知りたい方は、こちらの記事をご覧ください。

まとめ
今回は、 CSV ファイルの作成から操作する方法までを紹介しました。 Python を使った CSV ファイルの読み書き、そして、 pandas などのライブラリを使用して、データの整形・フィルタリング、データの集計・可視化まで、多岐にわたる操作が可能です。ここで紹介した CSV ファイルの操作が、データ分析を行なう際の一助となれば幸いです!
SHARE
新着記事
.png%3Fw%3D1086&w=3840&q=75)

.png%3Fw%3D1086&w=3840&q=75)
関連記事



キカガクラーニング
AI/データサイエンス学びはじめの方におすすめの記事



.png%3Fw%3D1070&w=3840&q=75)
コース一覧

注目記事

.png%3Fw%3D200&w=3840&q=75)
.png%3Fw%3D200&w=3840&q=75)

新着記事
.png%3Fw%3D200&w=3840&q=75)

.png%3Fw%3D200&w=3840&q=75)
.png%3Fw%3D200&w=3840&q=75)
.png%3Fw%3D200&w=3840&q=75)