
- SOTA の EfficientNet モデルよりも優れている
実装は現時点では公開されていませんが、今後こちらのレポジトリで公開される予定です。
Designing Network Design Spaces
paper : https://arxiv.org/pdf/2003.13678.pdf
written by : Ilija Radosavovic, Raj Prateek Kosaraju, Ross Girshick, Kaiming He, Piotr Dollár
subjects : Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG)
この記事について
こちらの記事は論文の翻訳をもとに、要約したものです。誤りがある場合も大いにありますので、その場合はご指摘いただけると幸いです。
研究者たちの意図はシンプルで、解釈可能性を追求し、シンプルでうまく機能し、設定を超えて一般化するネットワークを記述する一般的な設計原理を発見することを目指しています。
各問題設定に対して、個々のネットワークを設計して開発するのではなく、巨大で無限の可能性のあるモデルアーキテクチャの母集団からなる実際のネットワーク設計空間を設計することに焦点を当てました。
この巨大で無限の可能性のあるモデルアーキテクチャを AnyNet と呼びます。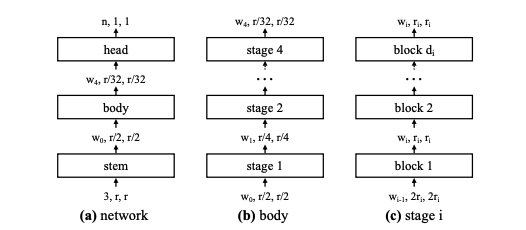
一般的に手動でのネットワーク設計では、畳み込み、ネットワークとデータのサイズ、深さ、残差などを考慮します。しかし、設計の選択肢が増える中で、最適化されたネットワークを手動で特定することは簡単でも効率的でもありません。ニューラルアーキテクチャ検索(NAS)は一般的なアプローチではありますが、検索空間の設定によって、検索できるモデルが制限されることがあります。さらに、NAS は必ずしも研究者がネットワークの設計原理を発見したり、ネットワークを一般化したりするのに役立つわけではありません。
そこで、VGG、ResNet、ResNeXtなどの標準的なモデル・ファミリーを想定して、ネットワークの構造(例えば、幅、深さ、グループなど)を探求することに焦点を当てています。そして、この AnyNet のさらに単純なモデルを持ち、解釈が容易かつ高精度モデルが RegNet です。
これまでの成果
では、どのようにして最適なネットワーク設計空間を設計すればよいのでしょうか。Facebook の AI チームは、彼らのアプローチを「マニュアルのネットワーク設計に似ていますが、人口レベルにまで高められています」と説明しています。
研究者は、初期のデザイン空間を入力とし、サンプリングとトレーニングによりモデル分布を収集します。デザイン空間の品質は、 Error Empirical Distribution Function(EDF)を用いて分析されます。デザイン空間のさまざまな特性が可視化され、経験的ブートストラップ法によって最適なモデルの範囲が予測された後、研究者はこれらの洞察を使用してデザイン空間を洗練させます。
Facebook の AI チームは、トレーニング時間の強化を行わず、同じトレーニング設定の下で EfficientNet との対照比較を行いました。2019 年に導入された Google の EfficientNet は、NAS とモデルのスケーリングルールを組み合わせて使用し、現在の SOTA を表しています。同等のトレーニング設定と Flops では、RegNet モデルは GPU 上で最大 5 倍高速でありながら、EfficientNet モデルを上回っていました。
モデルの成果
本論文では、ImageNet の検証セットを用いすべての実験を行います。さらにテストセットには ImageNetV2 を用いてモデルを評価しました。
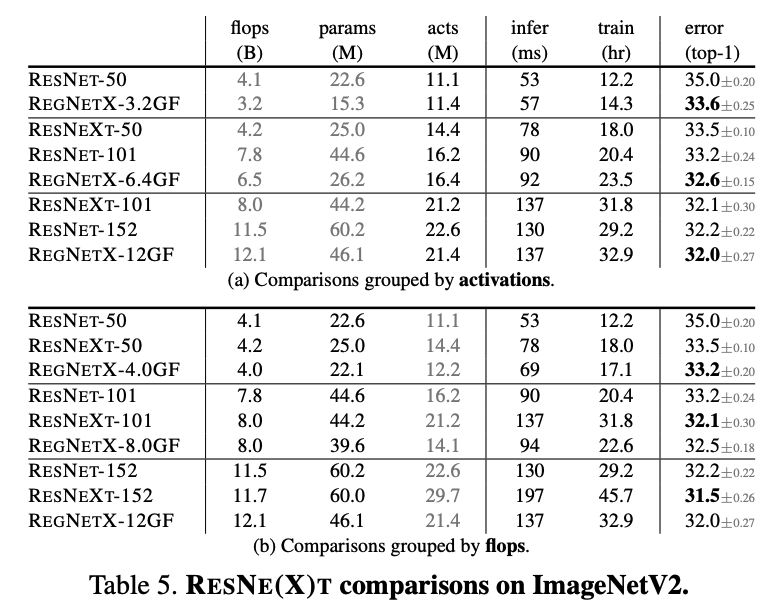
ResNe(x)t との比較では、概ね同じ値を維持していますが、ResNe(x)t が苦手な低計算領域では RegNet が良い成果を出しています。
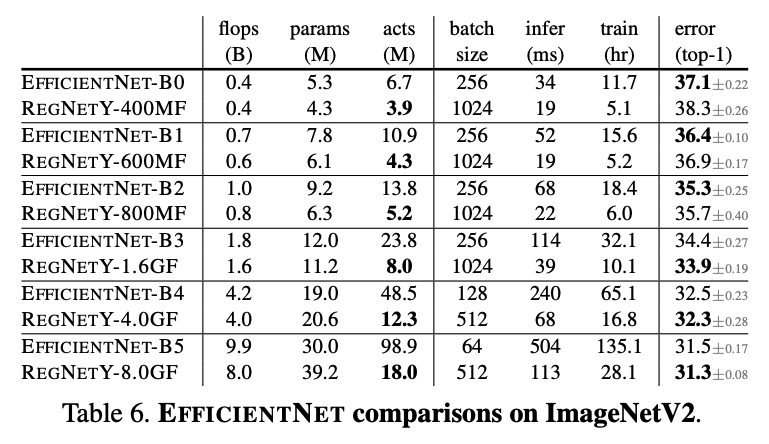
ネットワークを深くするごとに誤差は減少しています。特に注目したいのは infer(ms) の推論時間であり、SOTA (State Of The Art) である EfficientNet と同等の性能を持ちながら、GPU 上で約 5 倍の速度を持つことがわかりました。
まとめ
これまで画像認識、自然言語処理と深層学習の分野を問わずモデルを人工で構築してきましたが、本論文の主張の通り、探索自体をモデル化することで最適なアーキテクチャを導き出す可能性を感じます。
今後も本分野の発展は続いていくものと思われるため。引き続き注目していきたい。

