

こんにちは!株式会社キカガクの山村です!
この記事では、ビッグデータの活用において欠かすことのできない SQL について、入門的な内容を解説します!
- SQL・データベースの概要
- SQL の基本構文の読み方・書き方
- SQL を用いたデータ分析において基本となる手法
SQL を使ったデータ分析の必要性を感じるものの、自分で扱うには敷居が高いと感じている方や、データベースの設計・運用にこれから携わるエンジニアの方におすすめの内容です。
そもそも SQL とは?
SQL(エス・キュー・エル)とは、Structured Query Language の略で、直訳すると「構造化問合せ言語」と呼ばれるデータベース言語の一つです。データベース言語と聞くと難しく感じるかもしれませんが、データの保存・取得といった、データベースの操作を実行するための問合せ(=Query)文と考えてください。
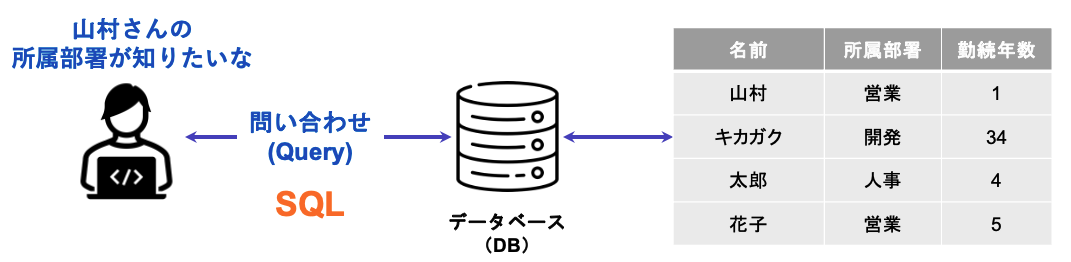
実は SQL は使用するデータベースによって様々な種類があります。Oracle や MySQL といった単語は聞いたことがある方も多いかもしれません。以下はよく使われるデータベースの一覧で、それぞれのデータベースに専用の SQL が用いられています。
| 名前 | 説明 |
|---|---|
| Oracle | Oracle 社のデータベース。商用で高いシェアを誇る。 |
| MySQL | Web を中心に、手軽に使えることで高い支持を得られている。 |
| PostgreSQL | Webシステムを中心に使用されている。 |
| SQLServer | Microsoft 社の製品。ASP などのシステムで用いられる。 |
| SQLite | Android などで用いられる RDB の簡易版。 |
他方で、SQL はデータベース言語として ISO(国際標準化機構)で規格化されています。
なので、一つのデータベース用の SQL を覚えたら、多少の違いはあれど、その他のデータベースでも同じように利用できます。
この記事では、SQL の中でも、無料で扱うことができ、かつ、分析機能が充実している PostgreSQL(ポストグレスキューエル)を使用します。
なぜ SQL を学ぶ必要があるのか?
現代のビジネス環境においては、企業や公的機関が生成・保有する膨大なデータを活用する能力がビジネスでの競争力を維持し、成長するために不可欠となっています。
データ活用のためには、膨大なデータを分析し、得られた結果を意思決定のプロセスに取り入れていくことが重要です。
SQL を用いることで、データを保存・管理するためのデータベースを構築することや、膨大なデータの中から必要な情報を取得し効果的に分析することが可能となります。
具体的には、Excel では扱うことが難しいほど大量のデータを扱うことや、BIツールから一歩踏み込んだより高度なデータ分析を行うことが可能となります。
近年では、SQL はデータサイエンティストやエンジニアだけが扱う言語ではなく、あらゆる業種で SQL でデータを操作することが求められることも少なくありません。
SQL を扱う上で必要となるデータベースの用語
SQL はデータベースを操作する言語であり、データベースとは切っても切れない関係です。これから SQL の構文を学ぶ前に、データベースについての基本的な用語を押さえておきましょう。
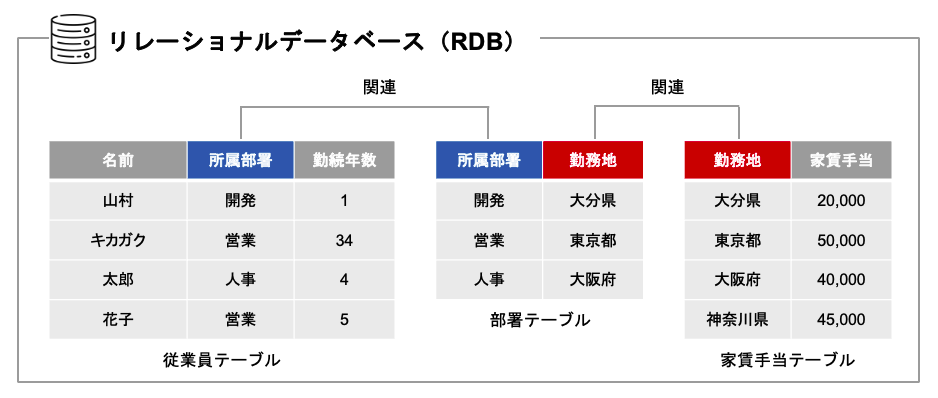
そもそもデータベースとは何でしょうか。データベースとは、データの集まりであり、最も代表的で広く利用されているのが、リレーショナルデータベース(RDB)です。
RDB は、テーブルと呼ばれる表形式のデータの集まりを複数持ち、テーブル同士がリレーション(関連)を持つようなデータベースです。以降、この記事では RDB を念頭において話を進めていきます。
少し難しくなってきましたが、一つずつ押さえていきましょう。
まず、テーブルというのは、データベースの基本単位で、以下のように行と列で構成される表のことを指します。Excel などを思い浮かべていただくと分かりやすいかと思います。
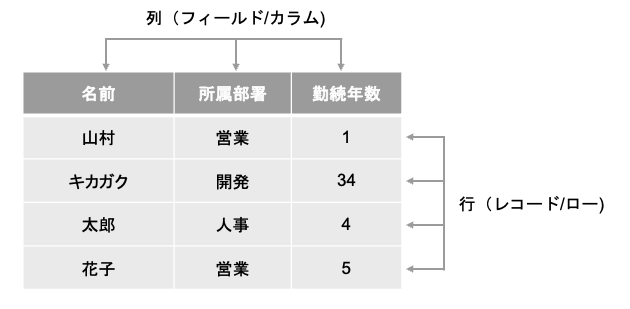
データベースの用語では、列をフィールド/カラム、行をレコード/ローと呼ぶこともあります。列方向には同じ種類のデータが並び、1 行がデータ 1 件と対応します。こうしたテーブルを複数持ち、テーブルの間に関係性があるものが RDB になります。
実際にテーブルを作成する時には、列ごとにデータの種類を指定します。このデータの種類のことをデータ型と呼びます。
例えば上の例では、顧客 ID には数値データが入り、氏名には文字列データが入る、のように指定します。こうすることで、意図しない種類のデータが入ることを防ぎ、データベースの品質を保つことができます。以下はよく用いられるデータ型の一覧です。
| 名称 | 型 | 概要 |
|---|---|---|
| integer | 数値型 | -2147483648 から +2147483647までの整数 |
| numeric | 数値型 | 小数点より上は131072桁まで、下は16383桁までの小数 |
| varchar(n) | 文字列型 | 可変長で上限が n 文字の文字列 |
| text | 文字列型 | 制限なし可変長の文字列 |
| date | 日付型 | 日付(時刻なし) |
| serial | 数値型 | 自動で連番を割り当てる 1 から 2147483647 までの整数 |
以上がデータベースの基本的な用語になります。テーブル、フィールド/カラム(列)、レコード/ロー(行)、データ型を把握しておきましょう。
これだけは押さえておきたい SQL の基本構文!
少し前置きが長くなりましたが、ここから実際に SQL の具体的な使用法をご紹介します。
ここでは SQL の 4 つの基本操作をご紹介します。この 4 つは Create, Read, Update, Delete の頭文字を取ってCRUD(クラッド)とも呼ばれ、データベースへのデータの格納や、格納されているデータを読み込むなど、SQL でデータを扱う上で基本となる操作となります。
SQL という言語の雰囲気や基本となる書き方・読み方を押さえていきましょう!
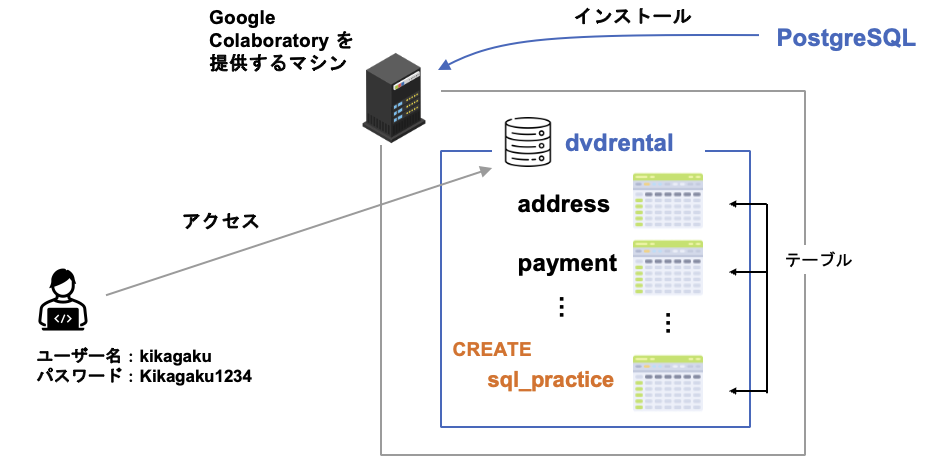
環境構築
はじめに SQL を実行するための環境構築(PostgreSQL のインストール、データベースの作成・テーブルの作成)を行いましょう。
実装は不要で、とりあえず SQL の構文が知りたい、という方は、本セクションは飛ばして次のセクションに進んでください。
今回は、Google アカウントさえあれば無料で手軽に実行環境を構築できる Google Colaboratory というサービスを使用します。

Google Colaboratory で新規でノートブックを作成し、以下のコードを実行してください。
%%capture
# PostgreSQL13 のインストール
!sudo cat > /etc/apt/sources.list.d/pgdg.list <<< "deb http://apt.postgresql.org/pub/repos/apt/ $(lsb_release -cs)-pgdg main"
!sudo curl https://www.postgresql.org/media/keys/ACCC4CF8.asc | sudo apt-key add -
!sudo apt-get -y -qq update
!sudo apt-get -y -qq install postgresql-13
!sudo pg_ctlcluster 13 main start
# sakila dataset ダウンロード(データ分析のセクションで利用)
!sudo mkdir dvdrental && cd dvdrental
!sudo wget https://www.postgresqltutorial.com/wp-content/uploads/2019/05/dvdrental.zip
!sudo unzip dvdrental.zip
# database 作成
!sudo -u postgres psql -U postgres -c "create database dvdrental;"
# database をリストア
!sudo -u postgres pg_restore -U postgres -d dvdrental dvdrental.tar
# ユーザーの作成
!sudo -u postgres psql -U postgres -c "create user kikagaku with superuser;"
!sudo -u postgres psql -U postgres -c "alter user kikagaku password 'Kikagaku1234';"
%load_ext sql
%config SqlMagic.autopandas = True
%sql postgresql://kikagaku:Kikagaku1234@localhost:5432/dvdrentalこのコードでは、大きく 4 つのことを行っています。
- PostgreSQL13 のインストール
- PostgreSQL 公式が用意しているサンプルデータベース(DVD rental database)をダウンロードし、dvdrental という名前でデータベースを作成
- データベースにアクセスするユーザーとパスワードの作成
- dvdrental に接続
次に、dvdrental の中にデータを格納するテーブルを作成します(データベースは関係性を持ったテーブルの集合体だったことを思い出してください)。
今回は sql_practice という名前で、次のような列とデータ型を持ったテーブルを作成します。
| 列名 | id | name | sex | age |
|---|---|---|---|---|
| データ型 | serial | varchar(40) | varchar(40) | integer |
%%sql
CREATE TABLE sql_practice
(
id serial primary key,
name varchar(40) not null,
sex varchar(40),
age integer
);コードの中身は以下のようになっています。比較しながら確認してみてください。
CREATE TABLE テーブル名
(
列名1 データ型 制約,
列名2 データ型 制約,
…
)SQL はデータベースの操作方法を示す命令文とテーブル名、列名などを組み合わせて記述していきます。上記では、CREATE TABLE が命令文、sql_practice がテーブル名、id が列名、serial, varchar(40), integer がデータ型を表します。
%%sql は Google Colaboratory 上で SQL を実行するためのマジックコマンドです。実際の SQL の本文は %%sql 以下のコードになります。
id 列の primary key や name 列の not null は制約と呼ばれ、データ型に加えて入力されるデータに制限を加える機能を持っています。例えば、not null 制約のついた列は空欄にすることができません。データ型と組み合わせて使用します。
以上で行ったことを図でもまとめておきます。
これでいよいよ SQL の構文を学ぶ準備が整いました。ここから SQL の 4 つの基本操作を一つずつご紹介していきます。
INSERT: データの新規登録
先ほど作成した sql_practice テーブルには 1 件もデータが登録されていません。INSERT を使ってデータを登録することができます。
INSERT INTO テーブル名 (追加する列名)
VALUES (値);実際にデータを登録してみましょう。
%%sql
INSERT INTO sql_practice (name, sex, age)
VALUES
('キカガク', '男性', 7), -- name = キカガク、sex = 男性、age = 7 のデータを登録
('太郎', '男性', 30),
('花子', '女性', 32);3 rows affected と表示されれば成功です。id は serial 型で自働で番号が振られるため、省略可能です。
なお、INSERT ではデータを1件ずつデータベースに格納しましたが、CSV ファイルなどに保存されたデータを一気に格納したい時もありますよね。
ファイルからデータを一度に格納する時は、COPY というコマンドが使用でき、基本的な使い方は以下になります。
COPY テーブル名 FROM ファイルパスINSERT と比べると少し応用的な構文になるので詳細は割愛しますが、興味のある方はぜひ PostgreSQL の公式ドキュメントなどで調べてみてください。
SELECT:データの取得
INSERT でデータを登録したものの、本当に登録されているのでしょうか。
SELECT と FROM を用いることでテーブルのデータを取得することができます。これら 2 つの命令文は SQL の中で最もよく使用する命令文になります。必ず使い方を押さえておきましょう。
SELECT 取得する列名
FROM テーブル名name 列と sex 列のデータを取得するには以下のコードを実行します。
%%sql
SELECT name, sex
FROM sql_practice;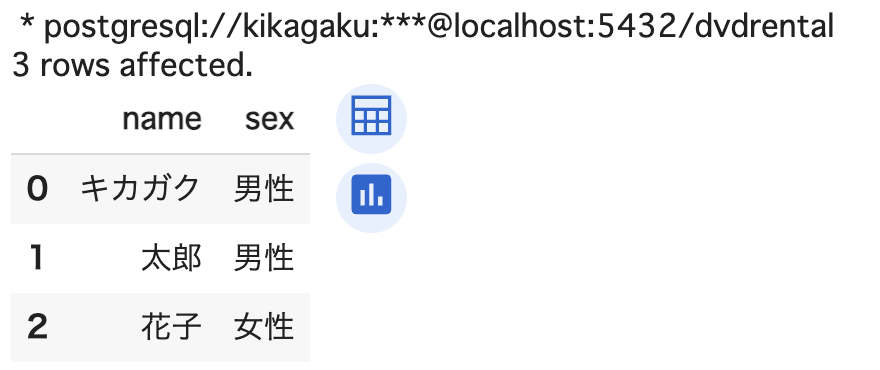
INSERT で登録したデータが取り出せました。全ての列のデータを取得するには、列名に * を指定します。
%%sql
SELECT *
FROM sql_practice;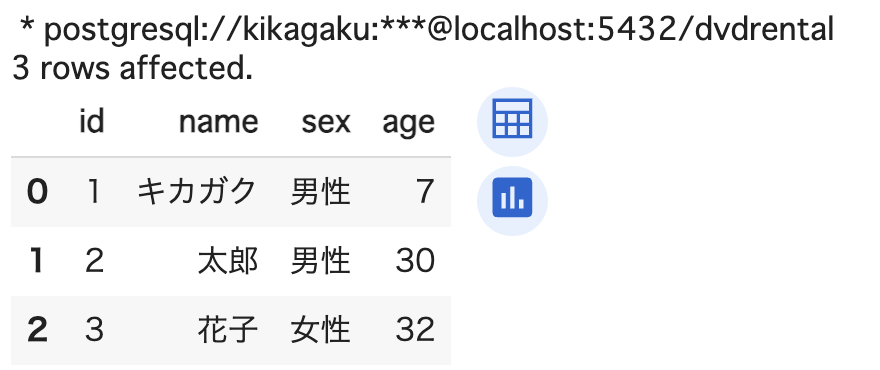
ここで、データの取得方法についてもう少し踏み込んで考えてみましょう。
今はデータが 3 件と少ないため、全て取り出して確認することができました。しかし、実際のデータベースには膨大なデータが登録されているはずです。
毎回全データを読み出すのは非効率ですし、データベースにも負荷がかかります。どんなデータが登録されているか最初の数行だけ確認したいといったケースもあるでしょう。また、いつも最初のデータから取得するのではなく、例えば「年齢の高い順」のようにソートして取得したいこともあるはずです。
そこで、取得するデータの件数の指定とソートの手法をご紹介します。
件数の指定は、LIMIT 件数 を使います。
%%sql
SELECT * FROM sql_practice
LIMIT 2;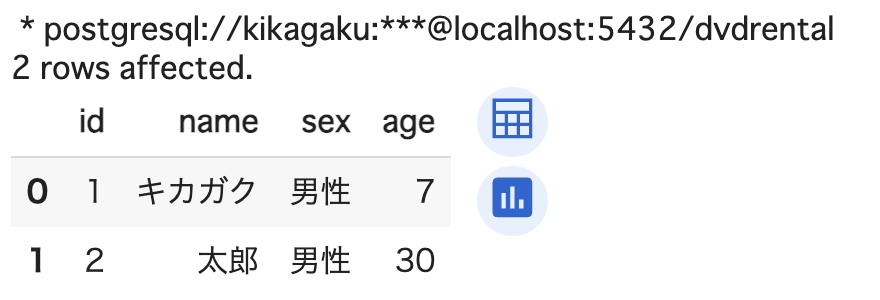
期待どおり 2 件のデータを取り出すことができました。
次にデータを年齢が高い順に並べ替え、年齢が高い順に 2 件取得します。先ほどのコードに ORDER BY 列名 オプション を追加します。
%%sql
SELECT *
FROM sql_practice
ORDER BY age DESC
LIMIT 2;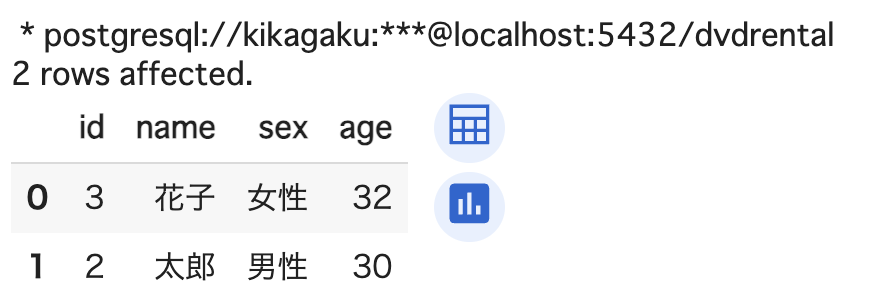
年齢が高い順にデータが 2 件取り出せました。なお、オプションの DESC は降順を表します。昇順の場合は ASC を用います。
このように、SELECT に LIMIT や ORDER BY を組み合わせることで、「上位○件」といったデータの取得が可能になります。
UPDATE:データの更新
次に登録したデータを更新する UPDATE をご紹介します。
UPDATE テーブル名
SET 列名 = 値;さて、ここでは年齢を更新することにします。データを登録した日から 1 年が過ぎたとして、全員の年齢に1 を加えて更新します。結果を表示するには SELECT を使います。
%%sql
UPDATE sql_practice
SET age = age + 1;
-- 結果の表示
SELECT *
FROM sql_practice;
無事に年齢に 1 を加算することができました。なお、特定の行の数値だけを更新するには条件抽出をする必要があります。条件抽出の方法については、データ分析入門のセクションで取り上げます。
DELETE:データの削除
基本操作の最後にデータの削除 DELETE をご紹介します。
DELETE FROM テーブル名DELETE を使うとテーブルの全てのデータが削除されます。注意して使うようにしてください。また、UPDATE と同様に、特定の行のデータだけを削除したい場合は、条件抽出をする必要があります。
SQL を使ったデータ分析入門
ここからは、SQL を使ったデータ分析入門として、DVD rental database のデータを用いて簡単なデータ分析を行いながら、SQL の構文をご紹介します。
今回は、customer テーブルと payment テーブルに注目します。DVD rental database 全体の概要については、公式サイトをご覧ください。
データの概要
最初に、SELECT を用いて、それぞれのテーブルから 3 件データを取得してデータの概要を把握します。
%%sql
SELECT *
FROM customer
LIMIT 3;
%%sql
SELECT *
FROM payment
LIMIT 3;
customer テーブルには名前、メールアドレス、住所などの顧客の基本情報が含まれていることが分かりました。payment テーブルには、顧客id や購入金額(amount)・購入日(payment_date)が含まれていることが分かりました。
今回は簡易的に 2 つのテーブルの先頭 3 行を表示してデータの概要把握を行いました。実際に手元のデータで分析を行う際は、データベースに関するドキュメント等も参考にしながら、テーブル間のリレーションや各テーブルのカラム名・データ型などを把握するようにしましょう。
以下で、これら 2 つのテーブルを用いた簡単なデータ分析を行いながら、SQL の構文をご紹介しましょう。具体的には「合計購入金額が 140 より大きい顧客を抽出し顧客リストを作成」してみることにします。
WHERE:条件抽出
まずは、テーブルから条件を指定してデータを取り出す方法をご紹介します。データ取得で用いた SELECT と WHERE を組み合わせます。
SELECT 列名
FROM テーブル名
WHERE 条件文WHERE の後の条件文には、様々な条件を入れることが可能です。例えば、customer_id が 100 番目の顧客のデータを指定して抜き出してみます。
%%sql
SELECT *
FROM customer
WHERE customer_id = 100;
このように、条件指定することで、条件に一致する行だけに注目してテーブルからデータを抽出することができます。他にも、範囲での指定や複数条件の組合せでデータを抽出することが可能です。条件文の基本的な書き方をまとめておきます。
| 条件文 | 意味 |
|---|---|
| 数値 a = 数値 b | 数値 a と数値 b が同じ値 |
| 数値 a != 数値 b | 数値 a と数値 b が同じ値でない |
| 数値 a < 数値 b | 数値 a が数値 b より小さい |
| 数値 a <= 数値 b | 数値 a が数値 b 以下 |
| BETWEEN 数値 a AND 数値 b | 数値 a と数値 b の間 |
| IN 数値 | 数値が存在する |
| NOT IN 数値 | 数値が存在しない |
| LIKE 文字列 | 文字列を含む |
| NOT LIKE 文字列 | 文字列を含まない |
| LIKE 文字列% | 文字列と前方一致 |
使用例をいくつか示します。コードを実行する際には、どのようなデータが抽出されるかイメージしながら実行してみてください。コードと出力結果の対応を見ながら知識の定着を図ることができます。
%%sql
-- どのようなデータが出力されるか、イメージしながら実行してみてください!
SELECT customer_id, first_name, last_name
FROM customer
WHERE customer_id > 95 and customer_id <= 100;
-- 範囲で指定し、複数条件を and で組合せ%%sql
-- どのようなデータが出力されるか、イメージしながら実行してみてください!
SELECT customer_id, first_name, last_name
FROM customer
WHERE last_name LIKE 'Sc%';
-- 文字列の前方一致で抽出GROUP BY:集計
次は、payment テーブルを使用して集計を行います。Excel で sum や average といった関数を使用するイメージです。SQL での書き方に慣れていきましょう。
SELECT 関数名(列名)
FROM テーブル名payment テーブルの amount 列(購入金額)の合計、平均、最大、最小や customer_id 列の行数(サンプル数)を算出します。
%%sql
SELECT
SUM(amount) AS "合計",
AVG(amount) AS "平均",
MIN(amount) AS "最小値",
MAX(amount) AS "最大値",
COUNT(DISTINCT customer_id) AS "customer_id の数"
FROM payment;
AS を使うことで列に名前をつけることができます。customer_id 列のデータには重複がある(同じ顧客が何度も購入している)ため、DISTINCT を用いて、重複を除いて行数をカウントしています。また、関数を組み合わせることもできます。
%%sql
SELECT
SUM(amount) / COUNT(DISTINCT customer_id) AS "一人あたりの購入金額"
FROM payment;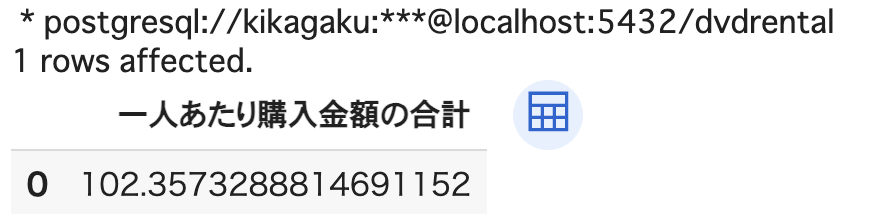
以上の集計はテーブルの列全体に対して行いました。では、顧客全体の合計購入金額ではなく、顧客ごとに合計購入金額を出したい場合はどうすればいいのでしょうか。
一つ考えられるのは、WHERE を使って顧客の ID を指定して行を抽出した後、SUM で合計を求める方法です。しかし、この方法では ID を一人ひとり指定することになります。顧客の数だけ SQL を実行するのは現実的ではありません。
そこで、カテゴリごとの集計をするための命令 GROUP BY を使います。GROUP BY を使えば顧客 ID ごとに購入金額の合計を算出できます。
SELECT 列名1, 関数(列名2)
FROM テーブル名
GROUP BY 列名1 -- 列名 1 のカテゴリごとに集計する%%sql
SELECT customer_id, SUM(amount)
FROM payment
GROUP BY customer_id
LIMIT 5; -- 表示件数が多いので、5 件のみ表示
顧客 ID ごとに合計購入金額を集計することができました。
目標は「合計購入金額が 140 より大きい顧客を抽出し顧客リストを作成」だったので、あとはこの中から合計購入金額 SUM(amount) が 140 より大きい顧客を抽出すればよさそうです。ここでの条件抽出には、HAVING 条件文 という新たな命令文を用います。
%%sql
SELECT customer_id, SUM(amount)
FROM payment
GROUP BY customer_id
HAVING sum_amount > 140.0 -- 合計購入金額が 140.0 より大きいという条件を指定
LIMIT 5; -- 表示件数が多いので、5 件のみ表示
これで合計購入金額が 140 より大きい顧客 ID を割り出すことができました。
条件抽出の際に WHERE と HAVING の 2 つをご紹介しました。どちらも条件抽出に用いる命令ですが、異なる点は命令が実行されるタイミングになります。具体的には、WHERE はオリジナルのテーブルに対して条件文が適用されるのに対し、HAVING は GROUP BY での集計後に条件文が適用されます。
以上で集計は終わりです。ここまでくればゴールまであと一歩です。
JOIN:テーブルの結合
それでは最後の仕上げとしてテーブルの結合をご紹介します。
payment テーブルを用いて集計した結果を見てみると、顧客 ID と合計購入金額のデータしかありません。これで十分な情報が得られているでしょうか。
例えば、データ分析の結果を用いて、合計金額が 140 より大きい顧客にクーポンを配布する、といった施策を実施する場合を考えましょう。この場合、ID だけでなく顧客の氏名や連絡先のデータも必要になりますよね。しかし、payment テーブルにはそういったデータは含まれていません。顧客のデータは customer テーブルに含まれているため、この 2 つのテーブルを連携させる必要があります。
2 つのテーブルを連携させる手法がテーブルの結合になります。具体的には JOIN という命令文が用意されています。
SELECT テーブル名1.列名,..., テーブル名2.列名,...
FROM テーブル名1
JOIN テーブル名2
ON テーブル名1.列名 = テーブル名2.列名少し構文が難しくなってきました。イメージを図で把握しましょう。

実際の使用例は以下になります。
%%sql
SELECT
c.customer_id, c.last_name, c.email,
p.amount
FROM customer AS c -- customer テーブルに c という名前をつける
JOIN payment AS p -- payment テーブルに p という名前をつける
ON c.customer_id = p.customer_id
LIMIT 5; -- 表示件数が多いので、5 件のみ表示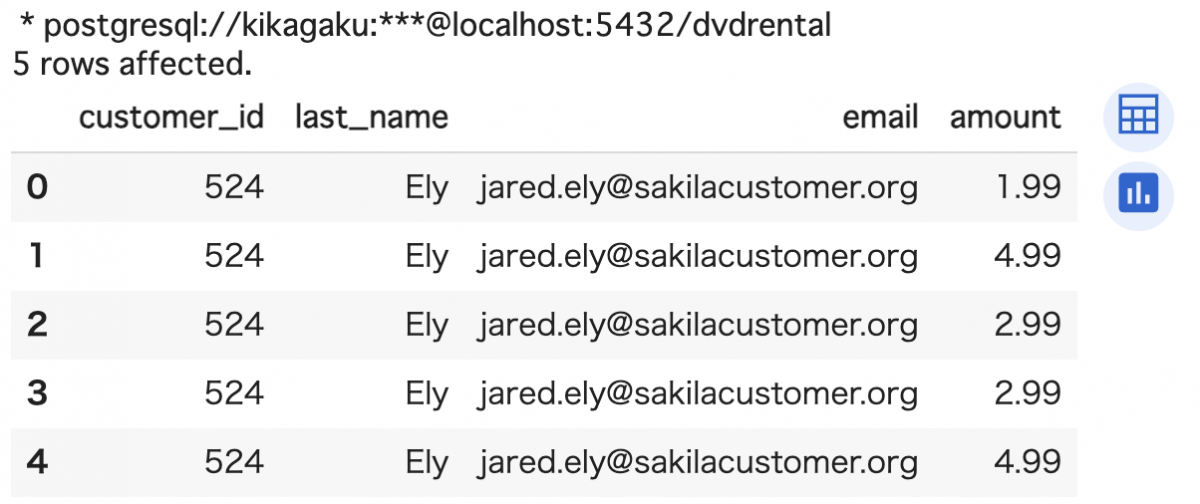
コードを順番に解説します。
SELECT で、customer テーブルの customer_id 列、last_name 列、email 列、payment テーブルの amount 列を表示するよう指定しています。 どのテーブルの列か明示的に指定するため、列名に c. や p. をつけています(c や p については後述のとおり)。その後、FROM と JOIN で結合するテーブル 2 つを指定します。この時、customer テーブルに c、payment テーブルに p と名前をつけています。最後に ON で結合する条件を指定します。今回は 2 つのテーブルの customer_id 列が一致するように結合しました。
今 2 つのテーブルを単に結合させただけなので、合計購入金額の条件を追加します。集計で紹介した GROUP BY と HAVING を追加すれば良いですね。
%%sql
SELECT
c.customer_id, c.last_name, c.email,
SUM(p.amount)
FROM customer AS c
JOIN payment AS p
ON c.customer_id = p.customer_id
GROUP BY c.customer_id
HAVING SUM(p.amount) > 140.0
LIMIT 5; -- 表示件数が多いので、5 件のみ表示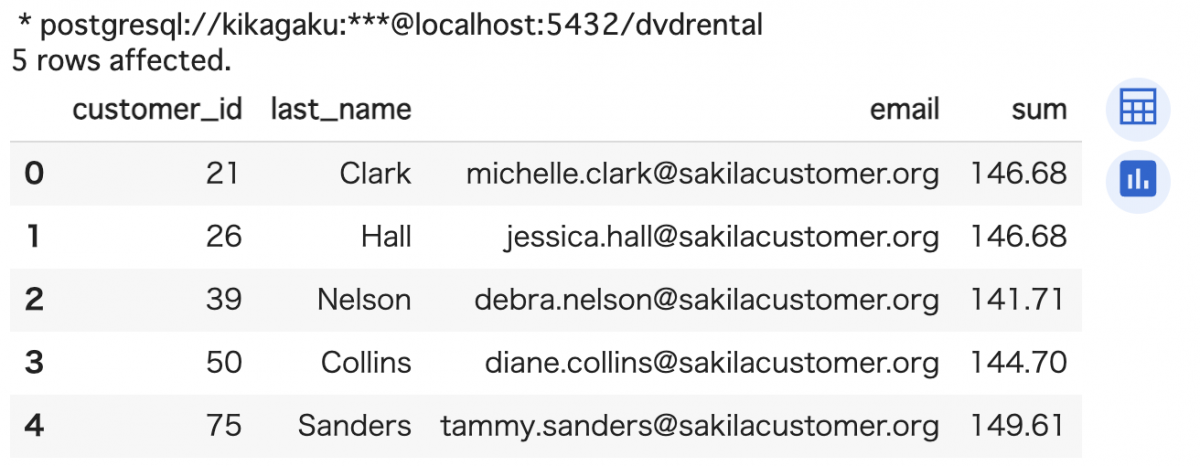
合計購入金額が 140 より大きい顧客のリストを作成することができました!
このように、基本の SELECT や FROM といった構文と GROUP BY や JOIN を組み合わせることで、様々なデータ分析が可能になります。
まとめと次へのステップ
SQL の概要、基本構文、SQL を使ったデータ分析をご紹介しました。 いかがだったでしょうか。SQL 使ってできることのイメージが湧き、コードの読み方・書き方がある程度掴めてきたと感じていただけたら嬉しいです。
次へのステップとしては、今回ご紹介した手法を使って、自分の持っているデータやサンプルデータを SQL で分析してみたり、データベースにデータを保存してみるなど、実際に手を動かしていただくことをおすすめします。
また、実践的な演習教材として、一般社団法人データサイエンティスト協会が提供している「データサイエンス100本ノック(構造化データ加工編)」をご紹介します。今回利用した Google Colaboratory 上での実装環境も提供されていますので、ぜひ挑戦してみてください!
最速で学びたい方:キカガクの長期コースがおすすめ

続々と転職・キャリアアップに成功中!受講生ファーストのサポートが人気のポイントです!
AI・機械学習・データサイエンスといえばキカガク!
非常に需要が高まっている最先端スキルを「今のうちに」習得しませんか?
無料説明会を週 2 開催しています。毎月受講生の定員がございますので確認はお早めに!
- 国も企業も育成に力を入れている先端 IT 人材とは
- キカガクの研修実績
- 長期コースでの学び方、できるようになること
- 料金・給付金について
- 質疑応答
まずは無料で学びたい方: Python&機械学習入門コースがおすすめ

AI・機械学習を学び始めるならまずはここから!経産省の Web サイトでも紹介されているわかりやすいと評判の Python&機械学習入門コースが無料で受けられます!
さらにステップアップした脱ブラックボックスコースや、IT パスポートをはじめとした資格取得を目指すコースもなんと無料です!

