【RAG】大規模言語モデルの能力を底上げする技術を初心者向けに徹底解説!

キカガク講師の船蔵颯です!本記事では、大規模言語モデルをさらに活用するための重要技術である RAG についてわかりやすくご説明したいと思います!

船蔵 颯
キカガクでは、Eラーニング教材の制作・管理責任者を担当しています。また、法人様向けの実プロジェクト型研修を様々な業種にわたって担当しています。
目次
RAGとは
RAG は、生成 AI の知識を補強するために、外部の知識源を検索・抽出する技術です。RAG の適用先としてはテキスト生成や画像生成など多岐にわたりますが、本記事では特に活用ケースの多いテキスト生成に焦点を当てて解説します。
RAG という言葉は Retrieval-Augmented Generation の略で、Retrieval は抽出、Augmented は補強、Generation は生成をそれぞれ意味する言葉です。RAG の仕組みは Retrieval-Augmented Generation という言葉そのままで、外部文書を抽出し、それによってモデルの知識を補強して生成するという建て付けになっています。
下図は、社内文書を参照して、社員からの質問に答える RAG システムのイメージです。
上記のようなシステムを構築することで、社内制度に特化したチャットボットを構築することができ、社内でのコミュニケーションコストの削減につながります。社員向けの情報伝達やカスタマーサポートなど、人間が全て対応するには負荷が大きい質問対応業務への活用が特にイメージしやすいでしょう。
本節では、RAG という技術についての一般的な理解を目指し、RAG には何ができて何ができないか、どのような仕組みで抽出・補強を行うのかといった点に力点を置いて説明します。
他の人工知能技術と同様、RAG も高速で発展し続けている技術です。本節の内容を理解することで、新たな技術が生み出されたときにその技術を理解する基礎体力が身につきます。
RAGの利点
OpenAI ChatGPT や Google Gemini など、私たちが普段使っているチャットボットは、大量のテキストデータを用いて事前に学習されており、さらに、プログラミングや数学の問題を解くなど、一定のスキルを要する問題が解けるように追加学習されているのが一般的です。学習に使われるデータの大部分は、Web サイトから取得したテキストデータや、チャットボットによって生成されたテキストです。
そのため、特定の企業が内部で管理しているマニュアルなど、一般公開されていない情報は当然ながら学習データに含まれておらず、チャットボットはその情報について知識を持っていません。
しかしながら、社内の制度やマニュアルについての質問に答えるチャットボットを構築する事例は存在します。そしてその多くでは、RAG が中心技術として活躍しています。
つまり、何か質問が与えられたときに、外部文書からその質問に関連する文章を抽出し、それによってチャットボットの知識を補強することができるのです。
ここで、RAG は大規模言語モデルを学習させる手法ではないという点に注意しておきましょう。RAG で行われる知識補強は、例えばプロンプトに外部文書を差し込むなどの形で、入力されるデータや計算の過程に対して行われます。つまり、大規模言語モデルを新たなデータで学習し直しているわけではありません。
大規模言語モデルは、大量のパラメータを持つ巨大な関数です。パラメータの値をうまく調整することで、自然な文章を生成することができるようになります。RAG は、このパラメータの値を調整し直しているわけではないということです。この意味で、RAG はノンパラメトリックな性能改善手法などと呼ばれます。
補足 – テキスト以外を扱う RAG
本記事ではテキストを対象とした RAG 技術について解説しますが、RAG 自体は画像や音声にも適用可能な枠組みです。入力されたデータと何らかの意味で関連するデータを検索し、それによって生成モデルの知識を拡張するというのが RAG の本質です。
補足 - パラメトリックな性能改善
いちど学習したモデルを、追加のデータで学習し直すことをファインチューニングと呼びます。ファインチューニングはパラメトリックな性能改善手法の代表格といえるでしょう。
社内制度など特定の領域についての質問応答を実現したい場合は RAG が手堅い一方で、差別的発言をしないよう調整したり、新しい言語を覚えさせたりなど、抜本的なアップデートにはファインチューニングが適しています。
RAGの仕組み
RAG システムは大きく抽出器(retriever)と生成器(generator)によって構成されます。まずは全体像を把握しましょう。
抽出器は質問と外部文書を何らかの表現(representation)に変換し、質問と類似していたり、関連している外部文書を抽出します。表現としてはベクトルを採用するのが一般的です。

生成器は、抽出器が抽出した外部知識によって知識が補完された状態で出力を生成します。典型的には、抽出された外部知識をプロンプトに挿入することで知識補完を行います。

以上、RAG システムの全体像をお伝えしました。次に、抽出器と生成器それぞれについて、実践において重要となるポイントを掘り下げていきます。
抽出器
抽出器として典型的なのは、ニューラルネットワークによる文埋め込みモデルです。ニューラルネットワークの中には、自然言語で書かれた文章を、その文章の意味を表現するベクトルへと変換するモデルが存在します。このようなモデルは文埋め込みモデルと呼ばれます。
文埋め込みモデルは、意味的に類似する二つの文章を、類似したベクトルへと変換するように学習します。
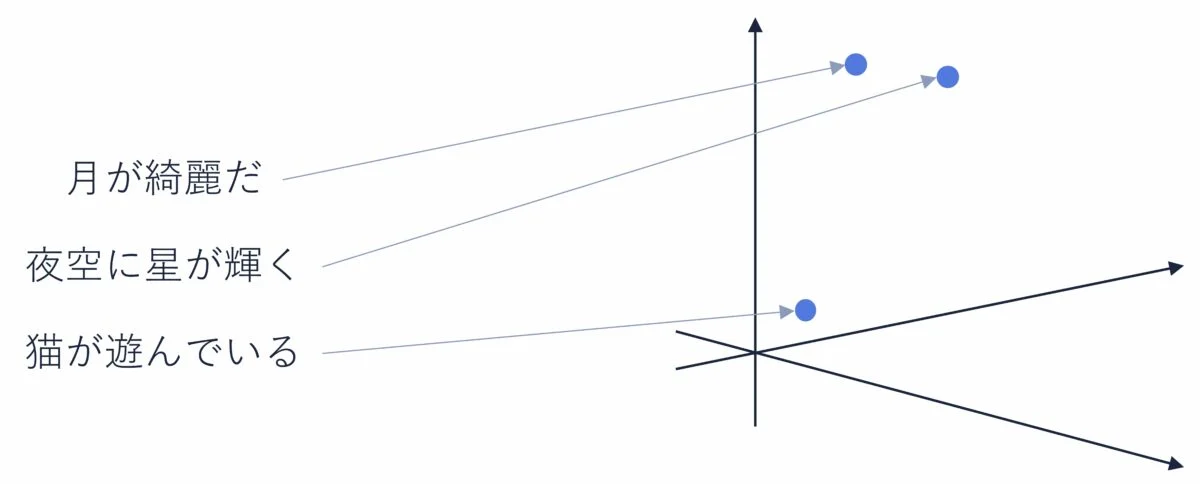
文章そのものはテキストであり、それらが意味的に類似しているかを直接計算することは難しいですが、ベクトル同士であれば距離や類似度を明確に定義することができます。文埋め込みモデルによって、二つの文章が似ているかという難しい問題を、ベクトル間の類似度計算というクリアな問題に帰着させていると見ることができます。
文埋め込みモデルを活用して質問と外部文書をベクトル化し、質問と類似する外部文書を抽出するというのが基本的な発想になります。距離や類似度を数値として算出できるベクトルを用いているからこそ、k近傍探索などの高速な検索アルゴリズムが活用できるというのも重要な背景です。
補足 - マルチモーダルな埋め込み
埋め込み(embedding)、つまり対象の特徴をベクトルで表現する技術はテキストを対象に発展してきました。さらに近年では、画像とテキストの両方を埋め込むことのできるニューラルネットワークが提案されています。代表的なモデルは OpenAI の提案した CLIP というモデルです。この技術によって、画像とテキストという本来異なるデータをひとつの空間に写像することができ、画像とテキストの間の類似度を計算するといったことが可能になります。
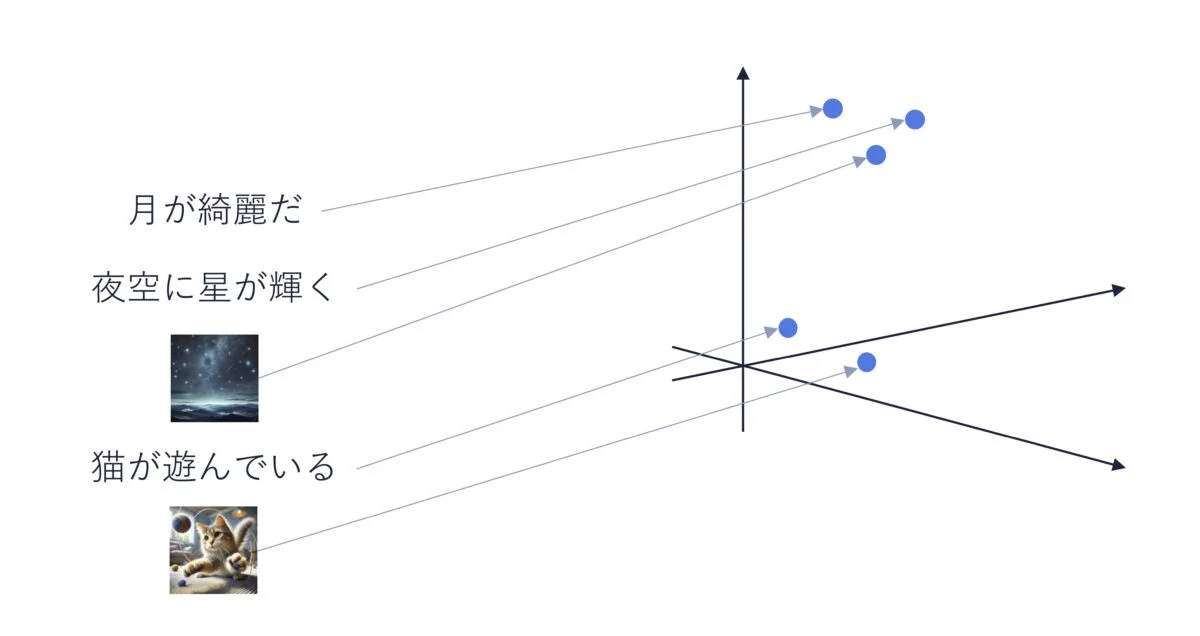
この技術が、まさに先ほどの補足で言及した、テキスト以外も扱うことができる RAG システムを支えています。
生成器
生成器としては大規模言語モデルを用いるのが一般的です。大規模言語モデルの実態は巨大なニューラルネットワークであり、多くのチャットボットの裏側では大規模言語モデルが稼働しています。
抽出器によって抽出された結果を生成器にどう与えるかには様々なパターンがありますが、抽出結果をプロンプト、つまりモデルに入力されるテキストの一部にするのが最も典型的といえるでしょう。

以上、抽出器と生成器それぞれについて、典型的な実現パターンをご紹介しました。RAG 技術の展開は凄まじく、ここまでにご説明したもの以外にも様々なバリエーションがあります。以降では、抽出器のバリエーションとして GraphRAG を、生成器のバリエーションとして Fusion-in-Decoder をご紹介します。
RAG 技術の展開と今後の課題
GraphRAG
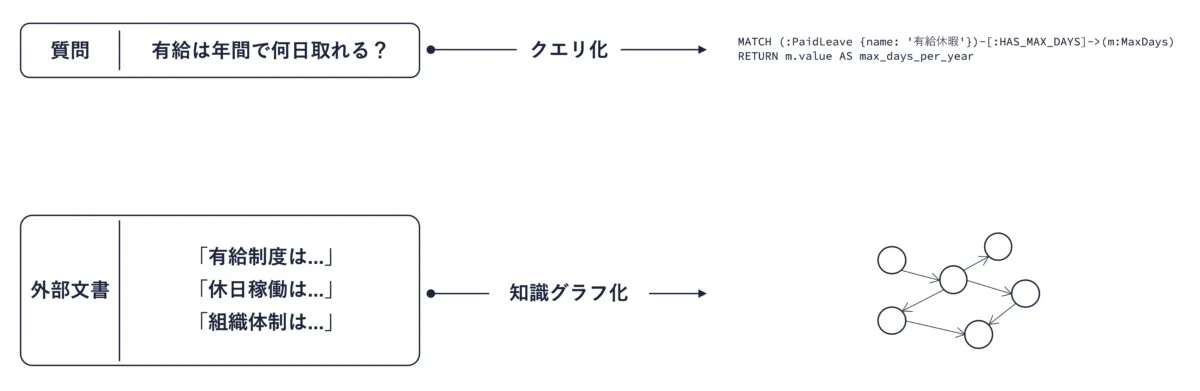
GraphRAG は、外部知識を知識グラフと呼ばれるグラフ構造で表現する手法です。下図は有給休暇についての社内制度を表現する知識グラフの例です。ここでは Neo4j というグラフデータベースを使用しています。丸で表現されている要素をノード、矢印で表現されている要素をエッジと呼びます。
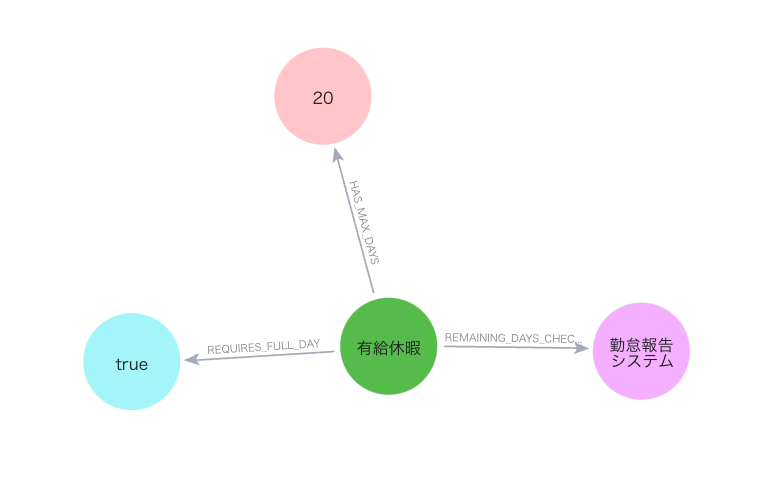
グラフ構造を扱うデータベースはグラフデータベースと呼ばれ、クエリと呼ばれる命令を提示することで知識抽出を行うことができます。Neo4j の場合であれば、以下のようなクエリを実行することで、有給取得の最大日数に関する要素を取り出すことができます。
MATCH (:PaidLeave {name: '有給休暇'})-[:HAS_MAX_DAYS]->(m:MaxDays) RETURN m.value AS max_days_per_year
このクエリは、「有給休暇」と HAS_MAX_DAYS 関係にあるノードを取得しており、結果として 20 というノードが得られます。
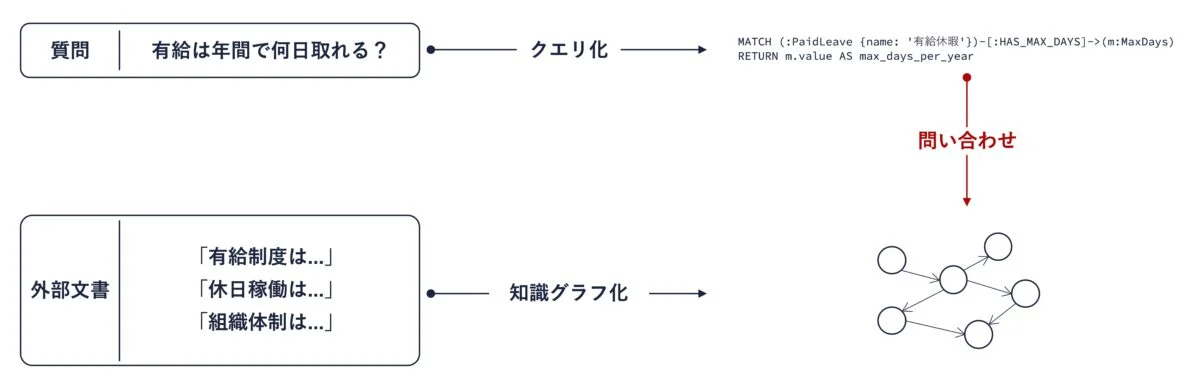
GraphRAG の重要なアイデアは、外部文書を知識グラフに変換する作業と、質問をクエリに翻訳するという作業のそれぞれを大規模言語モデルによって行うというものです。
知識グラフとクエリが揃えば、クエリを用いて知識グラフに問い合わせることで知識抽出が可能です。
GraphRAG は、プレーンな RAG システムの性能を上回るケースが報告されているという意味でももちろん重要ですが、知識グラフという、少なくとも 2000 年代前半ごろに歴史を遡る技術と大規模言語モデルが結びつき、新たな技術として顕現しているという意味でも私はたいへん興味深く感じています。
また、Wikidata をはじめとして大規模な知識グラフが公開されているため、これらを活用した RAG システムの構築にも、GraphRAG は適しているといえます。
Fusion-in-Decoder
Fusion-in-Decoder は、抽出結果のテキストそのものではなく、抽出結果のベクトル表現を生成器に与える手法です。下図はそのイメージです。
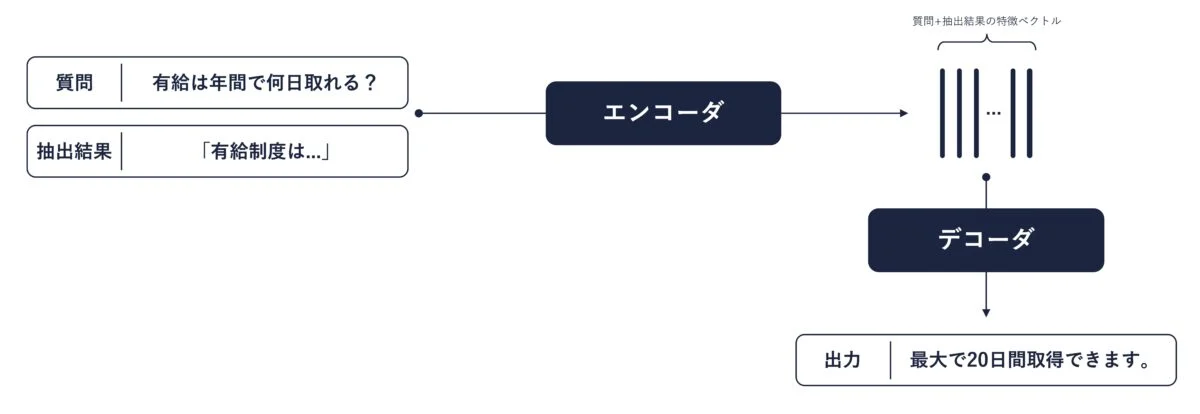
エンコーダは、テキストを入力としてベクトル列を出力するニューラルネットワークです。そしてデコーダは、ベクトル列を入力としてテキストを出力するニューラルネットワークです。
エンコーダは入力テキストの重要な特徴を抽出する役割を持っています。つまり、Fusion-in-Decoder はまずエンコーダが入力情報をきれいに整えて、その上でデコーダが回答を生成するという設計になっています。Fusion-in-Decoder の提案論文では、この設計にすることでシンプルな RAG よりも正確な質問応答ができると報告されています。
「ベクトル列」や「エンコーダ」、「デコーダ」など唐突に出現した単語に何だこれと思われた方もいらっしゃるかもしれません。これらのキーワードの背景には、大規模言語モデルを支える非常に重要なニューラルネットワークである Transformer が関係しています。Transformer についてはこちらの記事でも大変わかりやすく説明されています。ぜひ参考にご覧ください。
.png&w=3840&q=75)
RAG 活用における課題
RAG はチャットボットの知識拡張にあたってとても有用な技術ですが、もちろん完全ではありません。RAG システムを構築する上での前提条件も含め、克服の難易度が高い課題はあります。ここでは、特に多く遭遇する課題を提示します。
- 外部文書を活用できない:補足知識として参照する知識源がデータとして存在しない、あるいは適切に整備されていないケースがあります。
- 外部文書が常に正しいとは限らない:特に Web サイト上の膨大なテキストなどを外部文書として採用する場合、それらは必ずしも精査された文章ではなく、誤りを含んでいる可能性があります。
- 抽出器がうまく機能しない:万能な抽出器は存在せず、望むような抽出結果が必ず得られるわけではありません。
特に一点目の課題は、RAG システムの構築そのものを阻むという意味でクリティカルな課題です。上記のような課題を念頭に置き、目下取り組みたい事項に RAG システムを適用することが適切かどうかは慎重に検討する必要があります。
今後の展望
RAG は複数の処理コンポーネントを組み合わせている性質上、システム全体の性能に影響する要因は多岐にわたります。主要なものとして以下を挙げることができます。
- 入力される質問
- 抽出器
- 生成器
- 抽出結果と生成器の連携法
- 外部文書の管理法
今後は上記のような各側面にフォーカスした改善案が提案されていくと考えてよいでしょう。ある程度熟成された技術を活用する上では、ニューラルネットワークや自然言語処理といった基礎知識は必ずしも必要ありません。しかし、技術発展をタイムリーに追跡し、検証の手をいち早く回すためには、RAG システム全体を支える基礎的で、そして一見すると地味な知識が必要不可欠です。
ある程度の基礎理解を持っている分野と、そうでない分野とでは、先端技術を理解するのに必要な労力が全く違うことを私は身をもって感じています。キカガクの技術ブログには、初学者の方がスピーディに知見を得ていくための有益な記事がたくさんあります。ぜひ、他の記事も眺めてみてくださいね!
さらに学ぶために
以上、RAG システムの基礎知識から始めて、最近の技術的展開についてご説明してきました。最後に、RAG システムを実際に作るうえで参考になる情報源をご紹介します。
LangChain
LangChain は、大規模言語モデルを活用したアプリケーションを容易に構築・運用することができる Python ライブラリです。RAG システムだけでなく、エージェントと呼ばれる自走型のチャットボットを構築したり、実際に運用しているアプリケーションの挙動を観察するといったことが簡単なプログラミングで実現できます。
チャットボットを活用するためのライブラリは多数ありますが、現在は LangChain がスタンダードと言えるでしょう。公式ドキュメントはこちらのページです。
RAG 関連書籍
おすすめの書籍もご紹介します。直近出版された「大規模言語モデル入門 II」技術評論社が大変おすすめです。13 章で RAG が取りあげられており、RAG の基本理解に加えて LangChain での実装や、難しい問題である RAG の評価についてもボリューミーに説明されています。
前編である「大規模言語モデル」技術評論社では、RAG システムの根本を支えるニューラルネットワークの技術、特に Transformer について明快に説明されています。私自身にとっても、Transformer の理解の仕方は大変参考になりました。
まとめ
本記事では、大規模言語モデルの活用形態として特に柔軟かつ効果的な RAG という技術についてご説明してきました。深層学習に関連する他の技術領域と同様、RAG の世界も発展の速度は凄まじく、標準とされていたはずの考え方が新たな技術によってたやすく取って代わられることがあり得ます。
本記事が、進化を続ける技術と共に走っていくための基礎体力となることを願っています。
SHARE
新着記事
.png%3Fw%3D1086&w=3840&q=75)
.png%3Fw%3D1086&w=3840&q=75)

関連記事



キカガクラーニング
AI/データサイエンス学びはじめの方におすすめの記事



.png%3Fw%3D1070&w=3840&q=75)
コース一覧

注目記事

.png%3Fw%3D200&w=3840&q=75)
.png%3Fw%3D200&w=3840&q=75)

新着記事
.png%3Fw%3D200&w=3840&q=75)
.png%3Fw%3D200&w=3840&q=75)


.png%3Fw%3D200&w=3840&q=75)