【データ分析入門】 Pandas DataFrameの使い方をマスターしよう!

目次
こんにちは!
株式会社キカガク 機械学習講師の桑水流です!
今回はデータ分析の際に大活躍する pandas の DataFrame について初心者にもわかりやすく解説します。
基本的な概念や操作を身につけることでデータ分析に関する理解が深まり、業務にも活用できるようになること間違いなしです!
記事の最後にはデータ分析の勉強におすすめのサイトや書籍についての情報を載せていますので、ぜひ活用を意識しながら最後まで読んでみてください!
本記事はこんな方にオススメです
- DataFrame ってよく聞くけどいまいち理解できない方
- データ分析を始めてみたいけどデータの扱い方がわからない方
- データ分析の基本を学びたい方
pandas.DataFrame とは何か?
データ解析のための強力なツール
pandas は Python のデータ分析ライブラリの一つで、データ解析を行うための便利なツールの詰め合わせパックのようなものです。
その中でも DataFrame は以下の図のように行と列で構成される表形式のデータ構造であり、各列は異なるデータ型(数値、文字列、日付など)を持つことができます。
Excel や Google スプレッドシートを使ったことがある人ならイメージがつきやすいと思います。
初心者でも簡単にかつ、直感的にデータを操作することができます。
.png)
pandas.DataFrameの構造
3 つの要素で構成されている
PandasDataFrame の構造は、以下の図のように
- values : セルに格納されている値
- columns : 列のラベル (列に入る数値や文字列の名前)
- index : 行のラベル (行の通し番号のようなもの)
の三つの要素から構成されています。
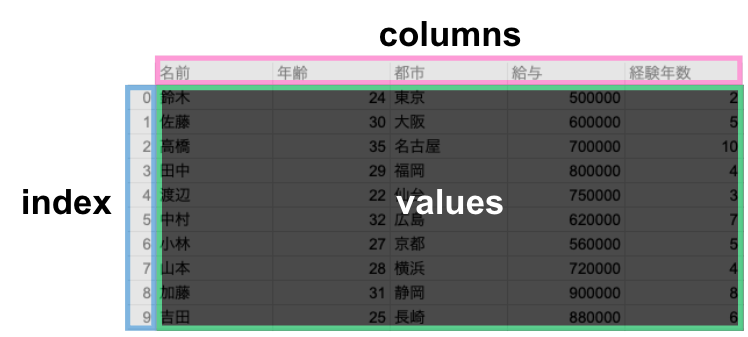
上の三つの要素が DataFrame を扱う際にかなり重要ですので図のイメージを押さえておきましょう。
それでは実際に DataFrame を作成して基本的な使い方について学んでいきましょう!
ここからは python を実行できる環境が必要です。
まだ環境設定ができていない方は以下の記事を参考に、設定不要の GoogleColaboratory を使用してみてください!
無料で簡単に Python 環境を整えることができます!

pandas.DataFrameの作成方法
DataFrame を作成する際にはいくつか方法があります。
辞書のリスト・辞書からDataFrame を作成
Pythonの辞書を使用してDataFrameを作成する場合、キーが列名となり、値がデータになります。
今回は「名前」・「年齢」・「出身地」をキーにして辞書の作成を行い、DataFrame へと変換しましょう。DataFrame への変換は pandas.DataFrame メソッドを使います。
import pandas as pd # 辞書を作成 data = { '名前': ['田中', '渡辺', '具志堅'], '年齢': [34, 23, 68], '出身地': ['大阪', '名古屋', '沖縄'] } # 辞書を DataFrame 型へ変換 df = pd.DataFrame(data) df
index | 名前 | 年齢 | 出身地 |
|---|---|---|---|
0 | 田中 | 34 | 大阪 |
1 | 渡辺 | 23 | 名古屋 |
2 | 具志堅 | 68 | 沖縄 |
実行結果
簡単に DataFrame を作成することができました!
辞書やリストが用意できれば DataFrame の作成は簡単に行うことができます。
python の辞書やリストについて詳しく知りたい方は以下の記事を参考にしてください。

Excel, CSV ファイルからの読み込み
実際に業務や学習でよく活用するのが、Excel や CSV 形式で保存されたデータを読み込んで DataFrame を作成する方法です。こちらを覚えておくと実際の業務でも活用しやすいと思います!
以下のコードで簡単に読み込むことができます。
# file.csv は自分のファイル名と path を指定 df = pd.read_csv('file.csv')
# file.xlsx は自分のファイル名と path を指定 df = pd.read_excel('file.xlsx')
読み込みたいファイルが作業フォルダ内にない場合は、パスを指定する必要があるので注意してください。
パスの指定がわからない方は以下の記事を参考にしてファイルの読み込みにチャレンジしてみてください。
.png&w=3840&q=75)
自分のローカル環境だけでなくネット上のデータについても以下のように URL を指定することで読み込むことができます。
今回は UCI machine learning repository で公開されているアヤメの花のデータを読み込んでみましょう。
import pandas as pd # ウェブ上のCSVファイルのURL url = "https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data" # カラム名 column_names = ['sepal_length', 'sepal_width', 'petal_length', 'petal_width', 'class'] # CSVファイルの読み込み data = pd.read_csv(url, names=column_names) # データの最初の5行を表示 data.head(5)
index | sepal_length | sepal_width | petal_length | petal_width | class |
|---|---|---|---|---|---|
0 | 5.1 | 3.5 | 1.4 | 0.2 | Iris-setosa |
1 | 4.9 | 3.0 | 1.4 | 0.2 | Iris-setosa |
2 | 4.7 | 3.2 | 1.3 | 0.2 | Iris-setosa |
3 | 4.6 | 3.1 | 1.5 | 0.2 | Iris-setosa |
4 | 5.0 | 3.6 | 1.4 | 0.2 | Iris-setosa |
実行結果
アヤメの花のデータを取得することができました。
この方法を使うことで自分でデータを持っていなくてもデータ解析が行えるので、ぜひ練習に活用してみてください!

pandas.DataFrameの操作
ここからは pandasDataFrame を操作する方法について紹介します。
実際の業務ではデータをそのまま使うのではなく、特定のデータを抜き出したり並べ替えたりして使用することが多いので、ここからの操作はしっかりと押さえておきましょう。
データの並び替え
まずはデータの並び替えです。データを年齢などの項目に基づいて並び替えたいな〜って思うことがよくあると思います。
そんな時はsort_values メソッドを使用することで、任意の列を基準に DataFrame を並び替えることができます。
最初に作成した DataFrame を使って並び替えを行ってみましょう。
# 辞書を作成 data = { '名前': ['田中', '渡辺', '具志堅'], '年齢': [34, 23, 68], '出身地': ['大阪', '名古屋', '沖縄'] } # 辞書を DataFrame 型へ変換 df = pd.DataFrame(data) # '年齢' 列で昇順にソートする sorted_df = df.sort_values(by='年齢') sorted_df
index | 名前 | 年齢 | 出身地 |
|---|---|---|---|
1 | 渡辺 | 23 | 名古屋 |
0 | 田中 | 34 | 大阪 |
2 | 具志堅 | 68 | 沖縄 |
実行結果
上から年齢が若い順にデータを並び替えることができました!
今回は昇順(数字が小さい順)で並び替えましたが、以下のようにsort_values の引数に ascending=False を指定することでデータを降順に並べ替えることができます。
# '年齢' 列で降順にソートする sorted_df = df.sort_values(by='年齢', ascending=False) sorted_df
index | 名前 | 年齢 | 出身地 |
|---|---|---|---|
2 | 具志堅 | 68 | 沖縄 |
0 | 田中 | 34 | 大阪 |
1 | 渡辺 | 23 | 名古屋 |
実行結果
データの結合
DataFrame では別々に作成された DataFrame 同士を結合または分割することができます。
データを結合する際には concat や merge を使用します 。
今回は使用機会が多い concat を用いて結合を行います。まずは異なる2つの DataFrame を上下(行方向)へ結合しましょう。
# サンプルデータ data1 = { '名前': ['田中', '渡辺'], '年齢': [34, 23], '出身地': ['大阪', '名古屋'] } data2 = { '名前': ['具志堅'], '年齢': [68], '出身地': ['沖縄'] } # DataFrameの作成 df1 = pd.DataFrame(data1) df2 = pd.DataFrame(data2) # 上下に連結 axis=0 : 行方向 concatenated_df = pd.concat([df1, df2], axis=0) # index をリセットして表示 concatenated_df.reset_index(drop=True)
index | 名前 | 年齢 | 出身地 |
|---|---|---|---|
0 | 田中 | 34 | 大阪 |
1 | 渡辺 | 23 | 名古屋 |
2 | 具志堅 | 68 | 沖縄 |
実行結果
異なる DataFrame を上下に結合することができましたね!
つぎは横方向(列方向)へ結合を行いましょう。横方向への結合はconcat の引数にaxis=1 を指定します。
# サンプルデータ data1 = { '名前': ['田中', '渡辺', '具志堅'], '年齢': [34, 23, 68] } data2 = { '出身地': ['大阪', '名古屋', '沖縄'], '職業': ['教師', 'エンジニア', '医者'] } # DataFrameの作成 df1 = pd.DataFrame(data1) df2 = pd.DataFrame(data2) # 横に連結 axis=1 : 列方向 concatenated_df = pd.concat([df1, df2], axis=1) # index をリセットして表示 concatenated_df.reset_index(drop=True)
index | 名前 | 年齢 | 出身地 | 職業 |
|---|---|---|---|---|
0 | 田中 | 34 | 大阪 | 教師 |
1 | 渡辺 | 23 | 名古屋 | エンジニア |
2 | 具志堅 | 68 | 沖縄 | 美容師 |
実行結果
このように concat を使用すると異なる DataFrame 同士を簡単に結合することができるため非常に便利です。
行や列の削除
DataFrame の中から不要な行や列を削除する方法について紹介します。
データ分析ではデータの入っていない行や列を削除したり、解析に不要なデータを削除することがよくありますのでしっかりと押さえておきましょう!
削除する際には drop メソッドを使用します。
こちらはconcat と同様に引数で axis= に 0 or 1 を指定することで、行方向か列方向か削除の方向を選ぶことができます。(デフォルトは axis=0)
# サンプルデータ data = { '名前': ['田中', '渡辺', '具志堅'], '年齢': [34, 23, 68], '出身地': ['大阪', '名古屋', '沖縄'], '職業': ['教師', 'エンジニア', '医者'] } # DataFrame を作成 df = pd.DataFrame(data) # DataFrame から '職業' の列を削除 df_dropped_column = df.drop('職業', axis=1) # DataFrame を表示 df_dropped_column
index | 名前 | 年齢 | 出身地 |
|---|---|---|---|
0 | 田中 | 34 | 大阪 |
1 | 渡辺 | 23 | 名古屋 |
2 | 具志堅 | 68 | 沖縄 |
実行結果
続いては最初の行を削除しましょう。
削除したい行の index 番号を最初の行なら drop(0) と指定することで削除ができます。
# サンプルデータ data = { '名前': ['田中', '渡辺', '具志堅'], '年齢': [34, 23, 68], '出身地': ['大阪', '名古屋', '沖縄'], '職業': ['教師', 'エンジニア', '医者'] } # DataFrame を作成 df = pd.DataFrame(data) # DataFrame から最初の行を削除 df_dropped_row = df.drop(0) # DataFrame を表示 df_dropped_row
index | 名前 | 年齢 | 出身地 | 職業 |
|---|---|---|---|---|
1 | 渡辺 | 23 | 名古屋 | エンジニア |
2 | 具志堅 | 68 | 沖縄 | 医者 |
実行結果
行や列の名前を変更
DataFrame は index や columns の名称を任意に変更することができます。
data = { '名前': ['田中', '渡辺', '具志堅'], '年齢': [34, 23, 68], '出身地': ['大阪', '名古屋', '沖縄'] } df = pd.DataFrame(data) # 列名を英語に変更 df.columns = ['Name', 'Age', 'Place_of_origin'] # インデックス名を "row_1", "row_2", "row_3" に変更 df.index = ['row_1', 'row_2', 'row_3'] # 表示 df
index | Name | Age | Place_of_origin |
|---|---|---|---|
row_1 | 田中 | 34 | 大阪 |
row_2 | 渡辺 | 23 | 名古屋 |
row_3 | 具志堅 | 68 | 沖縄 |
実行結果
データの分割
データの分割を行う際にはいくつか方法がありますが最低限覚えておきたい loc , iloc メソッドについて紹介します。
1. loc の使用例
loc は任意のラベルに基づいてデータを分割することができます。
今回は '年齢' が 40 歳以上かそれ未満かで DataFrame を分割してみましょう。
# サンプルデータ data = { '名前': ['田中', '渡辺', '具志堅', '佐藤', '鈴木', '高橋', '伊藤', '山本', '中村', '山田'], '年齢': [34, 23, 68, 29, 45, 31, 58, 42, 36, 27], '出身地': ['大阪', '名古屋', '沖縄', '東京', '福岡', '大阪', '名古屋', '東京', '福岡', '沖縄'], '職業': ['教師', 'エンジニア', '美容師', '教師', 'エンジニア', '美容師', '教師', 'エンジニア', '美容師', '教師'], '年収(万円)': [500, 300, 1000, 600, 400, 800, 700, 450, 900, 550] } # DataFrameの作成 df = pd.DataFrame(data) # 年齢が40歳以上のデータフレーム df_over_40 = df.loc[df['年齢'] >= 40] # 年齢が40歳未満のデータフレーム df_under_40 = df.loc[df['年齢'] < 40] print("DataFrame with age >= 40:") print(df_over_40) print("\nDataFrame with age < 40:") print(df_under_40)
DataFrame with age >= 40: 名前 年齢 出身地 職業 年収(万円) 2 具志堅 68 沖縄 美容師 1000 4 鈴木 45 福岡 エンジニア 400 6 伊藤 58 名古屋 教師 700 7 山本 42 東京 エンジニア 450 DataFrame with age < 40: 名前 年齢 出身地 職業 年収(万円) 0 田中 34 大阪 教師 500 1 渡辺 23 名古屋 エンジニア 300 3 佐藤 29 東京 教師 600 5 高橋 31 大阪 美容師 800 8 中村 36 福岡 美容師 900 9 山田 27 沖縄 教師 550
年齢を基準にして DataFrame を分割することができました!この方法はかなり直感的で便利なのでぜひ押さえておきましょう。
2. iloc の使用例
loc と iloc は似ていますが、データの指定方法が異なります。
loc がラベルを指定するのに対し、iloc は index を指定してデータの分割を行います。iloc の 'i' は index の 'i' と覚えるといいですね!
ではデータを最初の5行と後の5行で分割してみましょう!
: は 「から」を表します。
:5 は最初から 5 行目までを意味しています。5: は 5 行目から最後までを意味します。
# 最初の5行を含むデータフレーム df_first_half = df.iloc[:5] # 残りの行を含むデータフレーム df_second_half = df.iloc[5:] print("DataFrame with the first 5 rows:") print(df_first_half) print("\nDataFrame with the remaining rows:") print(df_second_half)
DataFrame with the first 5 rows: 名前 年齢 出身地 職業 年収(万円) 0 田中 34 大阪 教師 500 1 渡辺 23 名古屋 エンジニア 300 2 具志堅 68 沖縄 美容師 1000 3 佐藤 29 東京 教師 600 4 鈴木 45 福岡 エンジニア 400 DataFrame with the remaining rows: 名前 年齢 出身地 職業 年収(万円) 5 高橋 31 大阪 美容師 800 6 伊藤 58 名古屋 教師 700 7 山本 42 東京 エンジニア 450 8 中村 36 福岡 美容師 900 9 山田 27 沖縄 教師 550
iloc や loc を使用することで簡単にデータの分割を行うことができました!
DataFrame から条件を指定して抽出
DataFrame から特定のデータを取り出す際にはいくつか方法があります。
代表的なものとして query や loc などを使う方法があります。
1. query を使用する方法
query は条件式を '年収 >= 600' のように文字列として指定できるため、理解しやすいのが特徴です。
実際のコードは以下のようになります。
data = { '名前': ['田中', '渡辺', '具志堅', '佐藤', '鈴木', '高橋', '伊藤', '山本', '中村', '山田'], '年齢': [34, 23, 68, 29, 45, 31, 58, 42, 36, 27], '出身地': ['大阪', '名古屋', '沖縄', '東京', '福岡', '大阪', '名古屋', '東京', '福岡', '沖縄'], '職業': ['教師', 'エンジニア', '美容師', '教師', 'エンジニア', '美容師', '教師', 'エンジニア', '美容師', '教師'], '年収': [500, 300, 1000, 600, 400, 800, 700, 450, 900, 550] } df = pd.DataFrame(data) # query() メソッドを使用して年収 600 万円以上をフィルタリング high_earning = df.query('年収 >= 600') # 表示 high_earning
index | 名前 | 年齢 | 出身地 | 職業 | 年収 |
|---|---|---|---|---|---|
2 | 具志堅 | 68 | 沖縄 | 美容師 | 1000 |
3 | 佐藤 | 29 | 東京 | 教師 | 600 |
5 | 高橋 | 31 | 大阪 | 美容師 | 800 |
6 | 伊藤 | 58 | 名古屋 | 教師 | 700 |
8 | 中村 | 36 | 福岡 | 美容師 | 900 |
実行結果
2. loc を使用する方法
loc を使うと条件に合致するデータのうち特定の列のみを表示させるような複雑な設定も簡単に行うことができます。
# 年齢が30歳以上のデータに関して、名前と年齢、年収の列のみを選択 filtered_data = df.loc[df['年齢'] >= 30, ['名前', '年齢', '年収']] # 表示 filtered_data
index | 名前 | 年齢 | 年収 |
|---|---|---|---|
0 | 田中 | 34 | 500 |
2 | 具志堅 | 68 | 1000 |
4 | 鈴木 | 45 | 400 |
5 | 高橋 | 31 | 800 |
6 | 伊藤 | 58 | 700 |
7 | 山本 | 42 | 450 |
8 | 中村 | 36 | 900 |
実行結果
以上が DataFrame の基本的な操作になります!
さらに発展的なデータ分析を行うためには?
ここまで学んできた知識でデータの作成や操作を行うことができるようになりました。
さらに発展的なデータ分析を行いたい方は以下のサイトや書籍を参考に勉強を進めていただくのがいいと思います!
データ分析の学習におすすめのサイト・書籍
① Kaggle
一番のおすすめは実際にデータ分析を行ってみることです。習うより慣れろの精神で実践こそが一番の近道であると私は信じています。
中でも世界で最も有名なデータ分析コンペティションである Kaggle は練習問題やデータセットが豊富なので実践にはもってこいのサイトです!
下の記事を参考にするとつまずくことなくデータ分析を行うことができると思いますので、ぜひ参考にしてみてください!
.png&w=3840&q=75)
② データサイエンスの学び方
データ分析やデータサイエンスについて学びたいけどどうやって勉強すればいいかわからない方はぜひこの記事を参考にしてください!
データ分析をビジネスで活用する方法や、どうやって勉強すればいいかわからないという悩みを解決してくれる記事になっています!

.png&w=1920&q=75)
③ データサイエンス・データ分析にオススメの書籍
この記事ではデータサイエンスやデータ分析を学ぶために最適な書籍が紹介されていますのでぜひ参考にしてみてください!
.png&w=3840&q=75)

最速で学びたい方:キカガクの長期コースがおすすめ
.jpg&w=3840&q=75)
キカガクの長期コースはプログラミング経験ゼロの初学者が最先端技術を使いこなすAIエンジニアになるためのサポート体制が整っています!
実際に未経験からの転職・キャリアアップに続々と成功中です
まずは無料説明会で、キカガクのサポート体制を確認しにきてください!
説明会ではこんなことをお話します!
- 国も企業も育成に力を入れている先端 IT 人材とは
- キカガクの研修実績
- 長期コースでの学び方、できるようになること
- 料金・給付金について
- 質疑応答
まずは無料で学びたい方: Python&機械学習入門コースがおすすめこちら
.png&w=3840&q=75)
AI・機械学習を学び始めるならまずはここから!経産省の Web サイトでも紹介されているわかりやすいと評判の Python&機械学習入門コースが無料で受けられます!
さらにステップアップした脱ブラックボックスコースや、IT パスポートをはじめとした資格取得を目指すコースもなんと無料です!
SHARE
新着記事
.png%3Fw%3D1086&w=3840&q=75)

.png%3Fw%3D1086&w=3840&q=75)
関連記事



キカガクラーニング
AI/データサイエンス学びはじめの方におすすめの記事



.png%3Fw%3D1070&w=3840&q=75)
コース一覧

注目記事

.png%3Fw%3D200&w=3840&q=75)
.png%3Fw%3D200&w=3840&q=75)

新着記事
.png%3Fw%3D200&w=3840&q=75)

.png%3Fw%3D200&w=3840&q=75)
.png%3Fw%3D200&w=3840&q=75)
.png%3Fw%3D200&w=3840&q=75)