【初心者向け】Python でキカガクブログをスクレイピングして、記事一覧を取得してみた!

こんにちは、キカガク機械学習講師の小林です!
機械学習・データ分析を勉強している中で、よくあるお悩みの一つは「学んだことを活用するためのデータセットがない」という問題ではないでしょうか。そんなお悩みを解決できる手段の一つが「スクレイピング」です!しかしスクレイピングは便利な反面、利用するライブラリによっては環境構築が難しく、多くの方が頭を悩ませています。
そこで今回は、Python と BeautifulSoup を利用したスクレイピングについて、Google Colaboratory を用いて初学者向けに解説していきます。環境構築不要で、簡単に実装できますので、ぜひスクレイピングの最初の一歩として、この記事で学んでいきましょう。
こんな人におすすめ!
- これからスクレイピングを始めてみたい!
- 環境構築なしでスクレイピングに挑戦したい!
- WEB からデータを収集してみたい!
目次
データ収集の方法の 1 つ、スクレイピングに挑戦しよう
それではまずはスクレイピングについて、確認していきましょう。
スクレイピングとは、データ収集の方法の一つで、特にダウンロードした WEB ページから必要な情報を抜き出す作業のことです。例えば、 WEB ページに掲載されている株価やイイネ数などの情報を取得して時系列データを作成したり、記事一覧や文章自体を取得して自然言語処理に応用したり、という利用ケースが考えられます。
スクレイピング自体は、さまざまな言語で実装可能ですが、Python では BeautifulSoup や Selenium というライブラリを利用することが一般的です。また Google スプレッドシートで実施する方法やスクレイピング用のサービスもあるので、利用目的に合わせて実施方法は検討しましょう。
今回は、 BeautifulSoup を用いて、この「キカガクブログの記事一覧を作る」というタスクに挑戦してみようと思います。
Requests と BeautifulSoup でキカガクブログの記事一覧を作ってみよう
早速スクレイピングに挑戦してみましょう。まずはゴールの確認です。
最初からすべての記事の情報を集めるのは大変なので、今回は「トップページに表示されている記事一覧」の取得を最初のゴールとして、
- 記事タイトル
- 記事URL
- 公開日
を一覧にした CSV ファイルを作ってみようと思います。

環境構築・モジュールのインポート
- Google Colaboratory
- Python:3.7.13

今回利用するライブラリは次の2つです。
1. BeautifulSoup = スクレイピング用
2. Requests = WEB ページのダウンロード用
from bs4 import BeautifulSoup as bs4 import requests
流れとしては、次のステップで進めていきます
- 1Requests で WEB ページの html をダウンロードして、 BeautifulSoup で読み込む
- 2Chromeの検証機能でセレクタを取得する
- 3記事一覧を取得する
- 4記事のタイトル、URL 、公開日を取得する
- 5CSV ファイルに情報を保存する
STEP. 1 Requests で WEB ページの html をダウンロードして、 BeautifulSoup で読み込む
まずはトップページの html をダウンロードしてみましょう。
# 情報を取得したい URL を指定する url = 'https://blog.kikagaku.co.jp/' # Requests で URL 先の html を取得する res = requests.get(url)
# Requests の結果を確認する res # <Response [200]>
これだけで目標のページの html を取得することができます。
結果を確認すると、 200 と出力されています。これはステータスコードで、 200 は OK という意味です。ページが見つからない場合は 404 、アクセス権がない場合は 503 などが出力されます。
また取得した html は、次のコードで確認できます。
# 取得した html の中身を確認する res.text # <!doctype html>\n<html lang="ja">\n<head>\n<meta charset="utf-8">\n<meta http-equiv="X-UA-Compatible" content="IE=edge">\n
次に BeautifulSoup で内容を読み込ます。
soup = bs4(res.text, "html.parser")
URL さえ変えれば、同じ方法で他のページでも html が取得できます。
次に取得した html から必要な情報を抽出する方法を見ていきましょう。
STEP. 2 Chromeの検証機能でセレクタを取得する
BeautifulSoup では、 find や select というメソッドを通して、読み込んだ html から情報を取得していきます。ただそのためには、まずターゲットとなる WEB ページの構造を理解する必要があります。
そこで一度キカガクブログのトップページに戻り、取得したい情報がどこに掲載されているかを確認してみましょう。
ページの構造の把握には、 Chrome のデベロッパーツールが便利です。右クリックをして、メニューから「検証」を選ぶか、キーボードで F12 を押してみてください。
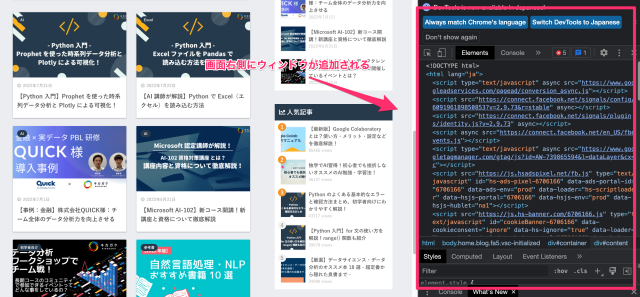
表示されたら、画像の手順で取得したい情報の html コードを確認しましょう。
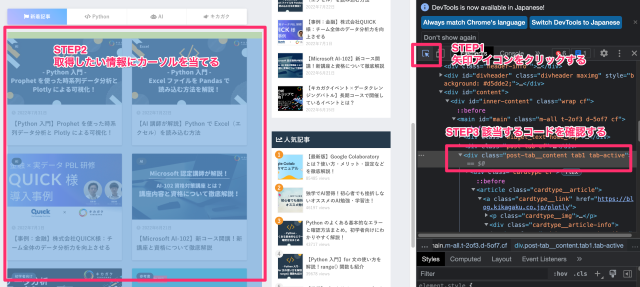
該当する箇所のコードを確認すると、全体が div タグで囲まれていて、class がいくつか設定されているのがわかります。
<divclass="post-tab__contenttab1tab-active">
この情報を頼りに、トップページに表示されている一覧情報の取得 (赤) -> 1 つずつの記事の取得 (青) 、という順序で進めていきます。
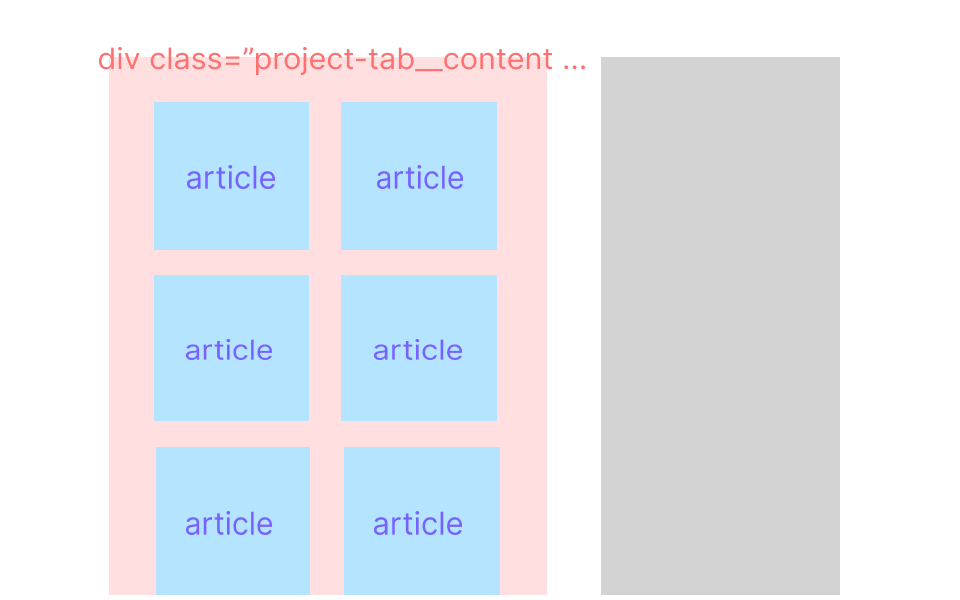
今回はこの作戦でいきますが、最初から 1 つずつの記事情報を取得するなど、他の情報の取り方もあるので、ぜひいろいろ試してみてください。
STEP. 3 記事一覧を取得する
では、次には記事の一覧を取得します。 BeautifulSoup では、 find メソッドを利用して取得したい情報のタグやクラスを指定できます。
今回取得したい情報は、
- div タグ
- class は 'post-tab__content'
と指定されたものの中にありそうです。
# find メソッドを利用して記事一覧を取得する article_list = soup.find("div", {'class' : 'post-tab__content'}) # 取得した情報を確認する print(article_list)
取得した情報を見ると、
- 今回取得したい記事がすべて含まれていること
- それぞれの記事のタイトル、URL、公開日が含まれていること
が確認できました。ここからさらに情報をしぼっていきます。
また、1 つの記事の情報は、 article タグでまとめられていることが確認できます。
<article class="cardtype__article"> <a class="cardtype__link" href="https://blog.kikagaku.co.jp/plotly"> <p class="cardtype__img"> <img alt="【Python 入門】Prophet を使った時系列データ分析と Plotly による可視化!" loading="lazy" src="https://blog.kikagaku.co.jp/wordpress/wp-content/uploads/2022/07/【共通】ブログのアイキャッチ画像-520x300.jpg"/> </p> <div class="cardtype__article-info"> <time class="pubdate entry-time dfont" datetime="2022-07-31" itemprop="datePublished">2022年7月31日</time> <h2>【Python 入門】Prophet を使った時系列データ分析と Plotly による可視化!</h2> </div> </a> <a class="dfont cat-name catid91" href="https://blog.kikagaku.co.jp/category/ai">AI</a> </article>
そこで取得した情報からさらに、find_all メソッドを使って article タグのリストを作ってみましょう。
# article_list から article タグのリストを作成する cards = article_list.find_all('article') # cards の中身を確認する cards[0]
<article class="cardtype__article"> <a class="cardtype__link" href="https://blog.kikagaku.co.jp/plotly"> <p class="cardtype__img"> <img alt="【Python 入門】Prophet を使った時系列データ分析と Plotly による可視化!" loading="lazy" src="https://blog.kikagaku.co.jp/wordpress/wp-content/uploads/2022/07/【共通】ブログのアイキャッチ画像-520x300.jpg"/> </p> <div class="cardtype__article-info"> <time class="pubdate entry-time dfont" datetime="2022-07-31" itemprop="datePublished">2022年7月31日</time> <h2>【Python 入門】Prophet を使った時系列データ分析と Plotly による可視化!</h2> </div> </a> <a class="dfont cat-name catid91" href="https://blog.kikagaku.co.jp/category/ai">AI</a> </article>
これで記事一覧の取得が完了しました。
では最後に 1 件ずつ、記事タイトル、URL 、公開日を取得していきましょう。
STEP. 4 記事のタイトル、URL 、公開日を取得する
取得した article タグの中身を見てみましょう。今回取得したい タイトル、 URL 、公開日はそれぞれどこに記載されているでしょうか。
情報の取得には、タグや属性、 class 、 id などが使えるので、それぞれ確認してみます。
- タイトル = h2 タグ
- URL = a タグ内の href 属性
- 公開日 = time タグ内の datetime 属性
BeautifulSoup では、タグは find メソッド、属性は get メソッドで取得できます。
cards[0].find('h2').text
cards[0].find('a').get('href')
cards[0].find('time').get('datetime')
ではトップページの記事すべての情報を取得してリストに格納してみましょう。
# 結果用のリストを作成する result = [['title', 'url', 'date']] # 各記事の情報を取得して、リストに格納する for card in cards: title = card.find('h2').text # タイトル url = card.find('a').get('href') # URL date = card.find('time').get('datetime') # 公開日 result.append([title, url, date]) # 最初の2件の結果を確認する result[1:3]
STEP. 5 CSVファイルに情報を保存する
無事トップページの情報が取得できていることが確認できました。
このままだと分析に使うことはできないので、今回は結果を CSV ファイルに出力しましょう。
import csv with open('output.csv', 'w', encoding="utf-8") as file: writer = csv.writer(file, lineterminator='\n') writer.writerows(result)
画面左側のフォルダアイコンをクリックすると、 output.csv ファイルが作成されています。こちらをダブルクリックすると、右側に一覧が表示されます。

無事取得できたことが確認できました。
【応用編】全件一覧を取得してみよう
今回はキカガクのトップページに掲載されているブログ記事の一覧を、スクレイピングを活用して作ってみました。 GoogleColaboratory と BeautifulSoup を活用すると環境構築不要で、簡単に取得できたと思います。
しかし実務でこのリストを活用することを考えると、トップページに表示される数件だけじゃなく、公開されている全件のリストを作りたいですよね。そこで最後におまけとして、全件一覧を取得するプログラムを掲載しています。ぜひ応用編としてご活用ください。
# 必要なモジュールのインポート from bs4 import BeautifulSoup as bs4 import requests # サーバー負荷軽減のために time をインポート import time
# url と 結果取得用のリストを作成 base_url = 'https://blog.kikagaku.co.jp/page/' result = [['id', 'title', 'url', 'date']] for i in range(13): url = base_url + str(i + 1) # アクセスする URL を指定 res = requests.get(url) # Requests で html を取得 soup = bs4(res.text, "html.parser") article_list = soup.find("div", {'class' : 'post-tab__content'}) cards = article_list.find_all('article') for card in cards: title = card.find('h2').text url = card.find('a').get('href') date = card.find('time').get('datetime') result.append([len(result), title, url, date]) time.sleep(5) # サーバー負荷軽減のため5秒待つ
import csv with open('output.csv', 'w', encoding="utf-8") as file: writer = csv.writer(file, lineterminator='\n') writer.writerows(result)
最後に
本記事では、Python を活用したスクレイピングのやり方について、実際にキカガクブログの記事一覧を作ることで学んできました。スクレイピングを使いこなすことで、 WEB 上に公開されている膨大なデータを収集できるため、ぜひ活用してみましょう!
ただしスクレイピングはサーバーに負荷をかけたり、法律に抵触する危険もあることから、利用には細心の注意を払うようにしましょう。特に取得したデータの利用方法などは、取得元の規約などを必ずご確認ください。
また、キカガクでは今回ご紹介したスクレイピングが学べる AI 人材育成長期コースを開講しています。
スクレイピングを含め、機械学習やディープラーニング、 Web アプリケーションの開発まで包括的に学びたい方は「AI 人材育成長期コース」の無料説明会にご参加くださいませ!
以上、 Python 学習している方々のお力添えになれば幸いです!
最速で学びたい方:キカガクの長期コースがおすすめ
.jpg&w=3840&q=75)
キカガクの長期コースはプログラミング経験ゼロの初学者が最先端技術を使いこなすAIエンジニアになるためのサポート体制が整っています!
実際に未経験からの転職・キャリアアップに続々と成功中です
まずは無料説明会で、キカガクのサポート体制を確認しにきてください!
説明会ではこんなことをお話します!
- 国も企業も育成に力を入れている先端 IT 人材とは
- キカガクの研修実績
- 長期コースでの学び方、できるようになること
- 料金・給付金について
- 質疑応答
まずは無料で学びたい方: Python&機械学習入門コースがおすすめこちら
.png&w=3840&q=75)
AI・機械学習を学び始めるならまずはここから!経産省の Web サイトでも紹介されているわかりやすいと評判の Python&機械学習入門コースが無料で受けられます!
さらにステップアップした脱ブラックボックスコースや、IT パスポートをはじめとした資格取得を目指すコースもなんと無料です!
SHARE
新着記事
.png%3Fw%3D1086&w=3840&q=75)

.png%3Fw%3D1086&w=3840&q=75)
関連記事



キカガクラーニング
AI/データサイエンス学びはじめの方におすすめの記事



.png%3Fw%3D1070&w=3840&q=75)
コース一覧

注目記事

.png%3Fw%3D200&w=3840&q=75)
.png%3Fw%3D200&w=3840&q=75)

新着記事
.png%3Fw%3D200&w=3840&q=75)

.png%3Fw%3D200&w=3840&q=75)
.png%3Fw%3D200&w=3840&q=75)
.png%3Fw%3D200&w=3840&q=75)