【動画生成AI】Stable Video Diffusion の使い方を初心者向けに徹底解説!

Stable Video Diffusionの使い方をわかりやすく解説!この記事を読めば、初心者でも簡単に動画生成ができるようになります。

目次
- Stable Video Diffusion とは?
- Stable Video Diffusion の概要
- Stable Video Diffusion の仕組み
- Stable Video Diffusion で実際に動画を生成
- Google Colab で Stable Video Diffusion を起動
- Stable Video Diffusion Web UI で画像から動画の生成
- Stable Video Diffusion の使い方のポイントと注意点
- Advanced Options を活用して任意の動画を生成する
- GPU の使いすぎに注意する
- モデルの選択で精度を向上する
- 参考資料
- 生成 AIの映像作品への活用事例
- マーベル・スタジオ Secret Invasion のオープニングムービー
- au 三太郎 CM が生成AI でアニメ化
- コカ・コーラの CM
- まとめ
Stable Video Diffusion とは?
Stable Video Diffusion の概要
Stable Diffusion(SD) がテキストから画像を生成するのに対し、本記事の主題である Stable Video Diffusion(SVD) は、テキスト、もしくは画像から動画を生成します。
現在(2024.04)は、画像から動画を生成する機能のみ公開されているので、本記事では実際に Stable Video Diffusion を用いて画像から自動で動画生成する過程を実施してみようと思います。
画像生成の Stable Diffusion についてはこちらの記事に詳しく記載していますので、ぜひご確認ください!


Stable Video Diffusion の仕組み
Stable Video Diffusion は、Stable Diffusion の発展版のため、まずは画像生成の仕組みについて簡単に確認しましょう。
Stable Diffusion では、完全にランダムに数値が与えられた画像から、ノイズを除去することで少しずつ画像を生成していきます。
そのため、この画像生成モデルはよく彫刻師に例えられます。(石灰から像を少しずつ削り出す彫刻師のイメージです。)

以上が Stable Diffusion の原理ですが、動画生成を実施する Stable Video Diffusion も基本的には同じ原理で動いています。
【Tips! : Stable Diffusion と Stable Video Diffusion の違い】
この両者は基本原理は同じですが、アーキテクチャには工夫の違いがあります。
SD は単純な空間畳み込みをメインとしたモデル構造を保持しており、一般的な画像生成のモデルの仕組みに則っています。ただし、SVD では空間畳み込みの後に、時間畳み込みを実施しています。これは、フレーム間の時間的なつながりをモデルが保持するための工夫であり、動画生成ならではの構造と言えます。この仕組みによって前後のフレームで違和感のない動画が生成できています。
詳細は論文を参照ください。
論文:Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
Stable Video Diffusion で実際に動画を生成
Google Colab で Stable Video Diffusion を起動
Stable Video Diffusion を簡単に使うために、ブラウザ上で Web UI が公開されています。今回はこちらを使って、動画生成を実施してみましょう。
1. サンプルコードのノートブックを開く
まずは以下のボタンをクリックして、Google Colab のノートブックを開いてください。
※ 必要に応じて「ファイル>ドライブにコピーを保存」を押すと、ご自身の Google Drive にコピーを作成いただけます。
2. コードを実行する。
次に、開いたノートブックのコードを実行しましょう。
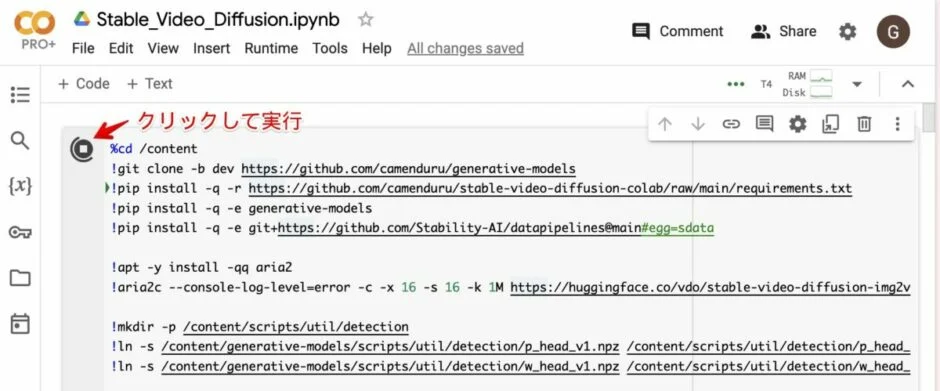
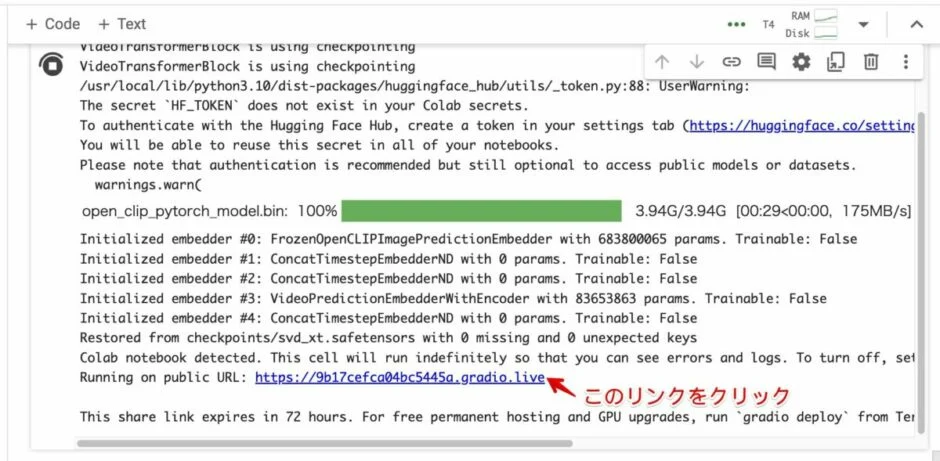
3. リンクをクリックして、Stable Video Diffusion Web UI を立ち上げる。
5分ほど待つと、以下のようなリンクがでてきますので、こちらをクリックして Web UI を起動します。
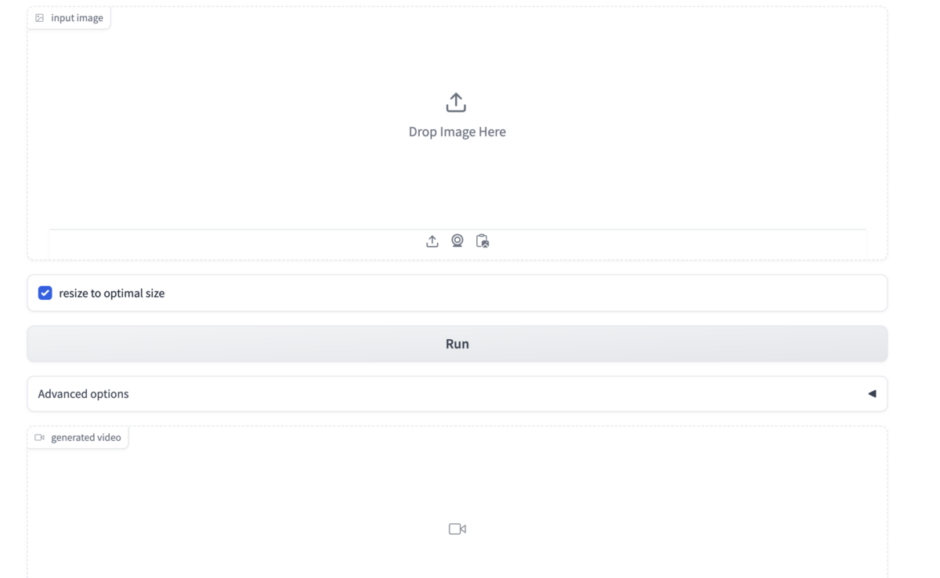
4. Stable Video Diffusion Web UI の起動が完了!
別のタブに以下のような画面が出てくると思います。これが、Stable Video Diffusion Web UI の画面になります。
Stable Video Diffusion Web UI で画像から動画の生成
以降は、Stable Video Diffusion Web UI の画面上で操作をしていきます。
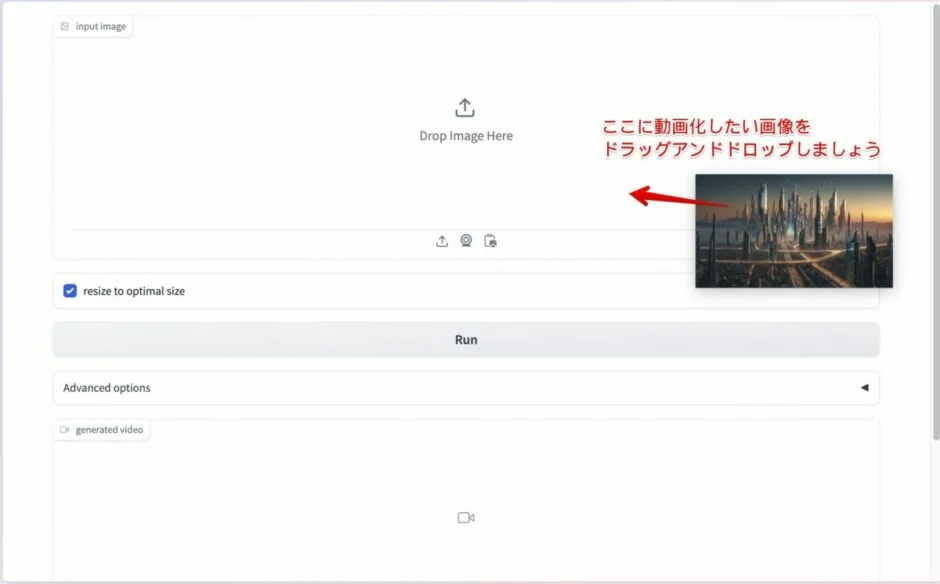
1. Web UI 上で動画化したい画像をアップロードする。
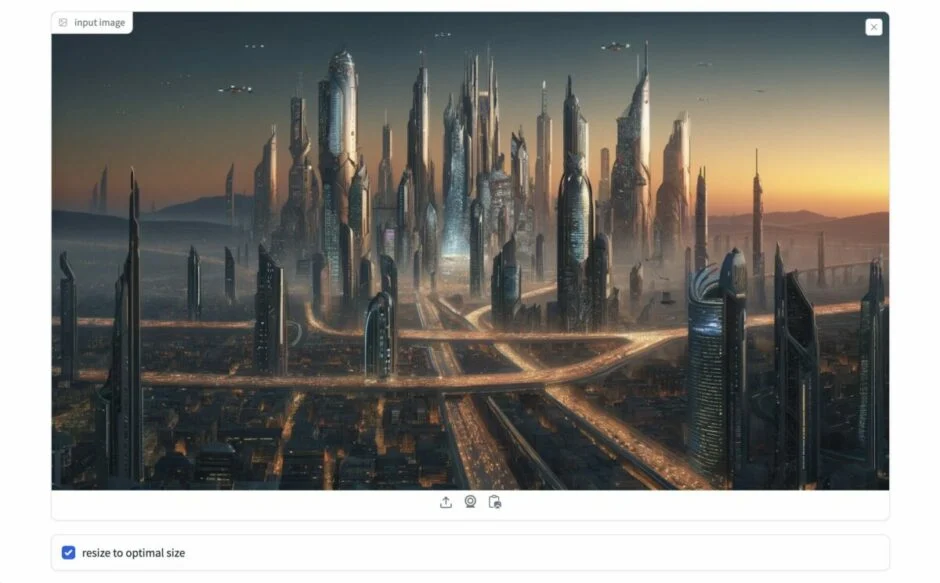
まずは、動画化したい画像をアップロードしましょう。画像はなんでも OK です。
「input image」の部分に動画化したい画像をドラッグアンドドロップするとアップロードできます。
2. 動画を生成する!
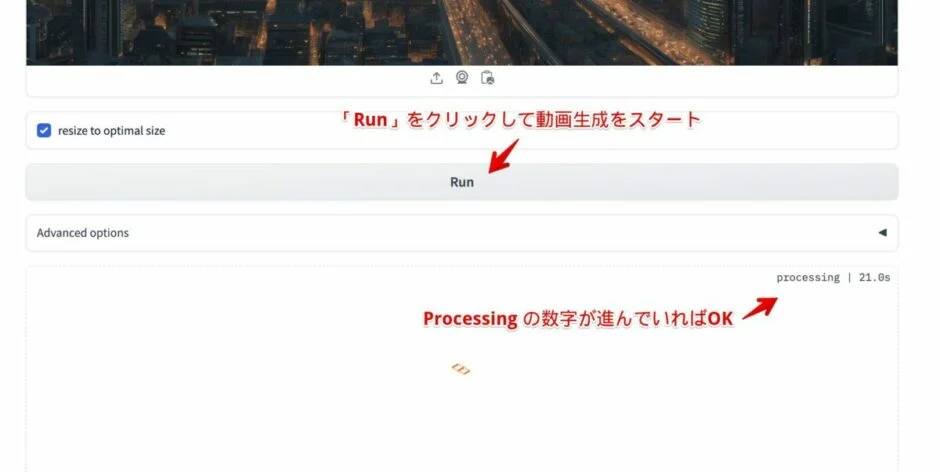
画像のアップロードができたら、「Run」ボタンを押して動画生成をスタート。完成まで 10分程かかります。
※ Processing の秒数が進んでいれば 動画生成が進行しています。
3. 生成された動画を確認してみる。
生成された動画を確認してみましょう。動画は右上のダウンロードボタンからダウンロードできます。
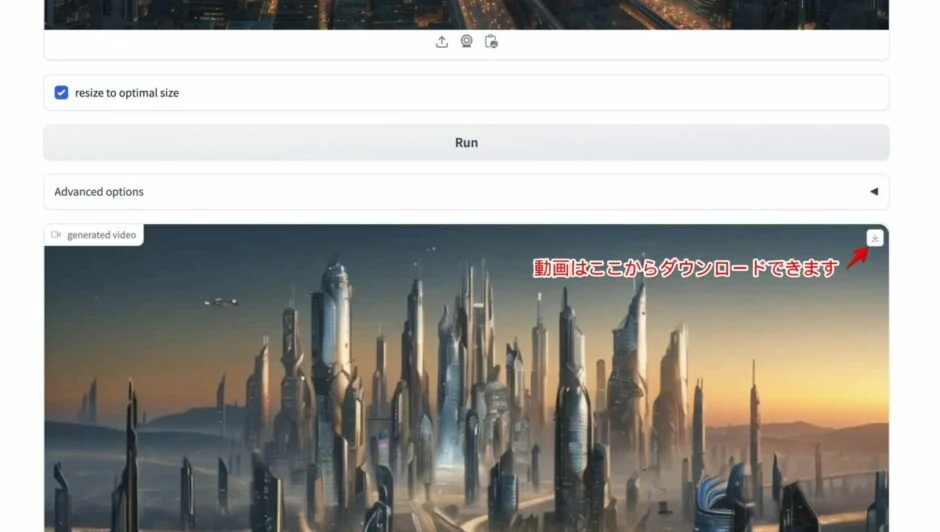
ダウンロードした動画を開いてみましょう。私の場合は以下のような動画が生成されました。

特になにも指定していないですが、ドローンが空を飛んでいたり、道路を車が走っていたりとかなりそれっぽい動画が生成されていることがわかると思います。また、枠外の部分についても違和感ない生成ができていますね。
Stable Video Diffusion の使い方のポイントと注意点
Advanced Options を活用して任意の動画を生成する
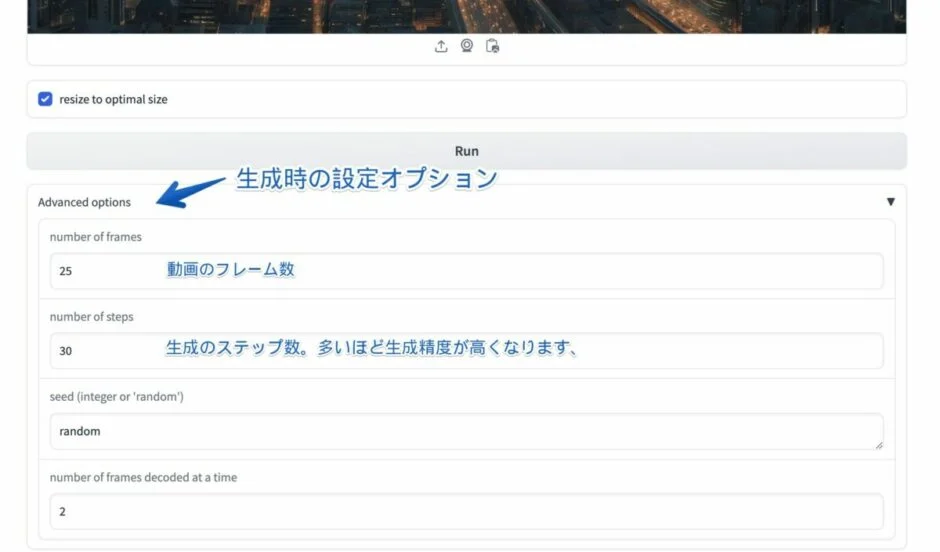
画像生成に比べるとオプションはまだ少ないものの、Stable Video Diffusion にも生成時の設定オプションがあります。
特に以下の 2 項目は、目指す動画によってカスタマイズできる部分なので、調整してみてください。
- number of frames : 動画のフレーム数を設定します。
- number of steps : 生成時のステップ数を設定します。高いほどステップ数が増えて、繊細な動画が生成されます。
GPU の使いすぎに注意する
動画生成は GPU をかなり使います。
Google Colab 等の GPU の利用量に制限のあるサービスをご利用の方はご注意ください。
モデルの選択で精度を向上する
Stable Video Diffusion には主に 3つのモデルが Hugging Face 上で公開されています。どのモデルを選択するかによって生成精度が変わりますので、是非試してみてください。
- stable-video-diffusion-img2vid
- stable-video-diffusion-img2vid-xt
- stable-video-diffusion-img2vid-xt-1-1
1 が最も軽量・高速ですが、その分 生成精度や生成できるフレームサイズに上限があります。
今回のノートブックでは「stable-video-diffusion-img2vid-xt」を利用しています。
参考資料
- https://github.com/camenduru/stable-video-diffusion-colab(参考実装)
- https://github.com/Stability-AI/generative-models(公式実装)
- https://huggingface.co/spaces/multimodalart/stable-video-diffusion/blob/main/app.py(公式実装)
- Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets(SVD 論文)
生成 AIの映像作品への活用事例
マーベル・スタジオ Secret Invasion のオープニングムービー
こちらの映像は、マーベルの新作ドラマ Secret Invasion(シークレット・インベージョン)のオープニングムービーです。
人間に擬態するエイリアンが地球へ侵略する
映像を見てみると、AIで生成した動画に特徴的な「映像のゆらぎ」をうまく活用して物語の不気味さを演出しているように感じます。
生成AIの不完全さもうまく活用した映像作品といえますね。
au 三太郎 CM が生成AI でアニメ化
テレビ CM や YouTube 広告でおなじみ au の三太郎 CM ですが、画像をアニメ風に変換する生成AI を用いて制作されています。
こちらの映像は、LoRA(ローラ)という画像生成AI を用いて、人気イラストレーターの松本ぼっくりさんの作品を 200 枚学習し、制作されているそうです。
映像フレームの一枚一枚をアニメ風に変換するというアルゴリズムが用いられています。
そのため、今回紹介した Stable Video Diffusion とは生成の方法が異なりますが、このようにして生成AI を映像作品に活用している例として興味深かったのでご紹介しました!
コカ・コーラの CM
こちらは、2023 年 3 月に公開されたコカ・コーラの CM です。「名画がまるで生きているかのよう」と話題になりました。
Stable Video Diffusion を開発している Stability Japan の公式 X でも紹介されているように、映像の加工に Stable Diffusion が使われているそうです。
映像の制作過程も公開されていたので、興味のある方はぜひ見てみてください!
Stable Diffusionを使ったコカ・コーラのCMがすごすぎる pic.twitter.com/bsBzgd3pSr
— Stability AI Japan (@StabilityAI_JP) May 12, 2023
まとめ
今回は、テキスト、もしくは画像から動画を生成する Stable Video Diffusion(SVD) について概要や使用方法についてご紹介しました。
初心者でも簡単に動画生成ができるツールですので、動画生成に触れてみたい!という方はぜひ試してみてください!
SHARE
新着記事
.png%3Fw%3D1086&w=3840&q=75)


関連記事



キカガクラーニング
AI/データサイエンス学びはじめの方におすすめの記事



.png%3Fw%3D1070&w=3840&q=75)
コース一覧

注目記事

.png%3Fw%3D200&w=3840&q=75)
.png%3Fw%3D200&w=3840&q=75)

新着記事
.png%3Fw%3D200&w=3840&q=75)


.png%3Fw%3D200&w=3840&q=75)

目次
- Stable Video Diffusion とは?
- Stable Video Diffusion の概要
- Stable Video Diffusion の仕組み
- Stable Video Diffusion で実際に動画を生成
- Google Colab で Stable Video Diffusion を起動
- Stable Video Diffusion Web UI で画像から動画の生成
- Stable Video Diffusion の使い方のポイントと注意点
- Advanced Options を活用して任意の動画を生成する
- GPU の使いすぎに注意する
- モデルの選択で精度を向上する
- 参考資料
- 生成 AIの映像作品への活用事例
- マーベル・スタジオ Secret Invasion のオープニングムービー
- au 三太郎 CM が生成AI でアニメ化
- コカ・コーラの CM
- まとめ