たった 3 行で性能向上!torchvision のデータ拡張で AI を学習させてみた!
.png%3Fw%3D1110&w=3840&q=75)
皆さんこんにちは!
キカガクで機械学習講師をしております倉田です。
今回は、データ拡張 ( Data Augmentation ) を使って、モデルを学習する方法を超簡単にお伝えしようと思います!
データ拡張とはなにかについては前回の記事で説明しておりますので、ぜひご参照ください!

それでは、実際にデータ拡張を実装し、モデルに学習させてみましょう!
torchvision でデータ拡張して精度を上げる方法
事前準備
でははじめに、使用するライブラリを読み込んでいきます。
import torch import torch.nn as nn import torch.nn.functional as F import matplotlib.pyplot as plt from torchvision.models import vgg16
今回、モデルの構築には、Pytorch Lightning というライブラリを利用しますので、こちらをインストールしておきます。
!pip install pytorch-lightning
インストールできたら、Pytorch Lightning と torchvision を読み込んでいきます。
import torchvision from torchvision import transforms, datasets import pytorch_lightning as pl
データ拡張する
それでは、今回最大のポイントであるデータ拡張を行っていきましょう!
やり方自体はとても簡単で、次の2ステップで完了します。
データ拡張の手順
- データセットの変換内容の定義
- 変換内容に基づいて、データセットを変換&取得
では、実際にやってみましょう!
1. データセットの変換内容の定義
# データセットの変換を定義 DA_transform = transforms.Compose([ transforms.RandomHorizontalFlip(p=0.5), transforms.CenterCrop(24), transforms.Resize(32), transforms.ToTensor() ])
ここでは、画像データにどのような変換をかけてデータ拡張を行うかを定義しています。
今回の場合だと、以下のデータ拡張を施しています。
- transforms.RandomHorizontalFlip(p=0.5) : 50%の確率で、左右反転する
- transforms.CenterCrop(24) : 24*24 のサイズで、中心を切り出す
- transforms.Resize(32) : 24*24 の画像を 32*32 のサイズに引き伸ばす
- transforms.ToTensor() : Tensor 型に変更
つまり、やり方としては、transforms.Compose() の中に、データ拡張のコードを記入していくだけで、好きな拡張を実装することができます。
変換内容に基づいて、データセットを変換&取得
では、 1 で定義した変換を実際にデータに施していきましょう。
やり方としては、取得するデータセットの引数に transform = DA_transform と追加するだけで、実装できます。
# データセットの取得 train_val = datasets.CIFAR10('./', train=True, download=True, transform=DA_transform) test = datasets.CIFAR10('./', train=False, download=True, transform=transforms.Totensor())
なんと!データ拡張はこれで完了です!
変換後の画像を見る前に、一度データセットを作ってしまいましょう!こちらはデータ変換とは関係ない処理ですので、コピペでもOKです!
データセットの準備
ここでは、主に以下の 2 つの処理を実装しています。
- 訓練データセットを、訓練用と検証用に分割する。
- Data Loader を作成する。
# train と val に分割 pl.seed_everything(0) n_train, n_val = int(len(train_val)*0.8), int(len(train_val)*0.2) train, val = torch.utils.data.random_split(train_val, [n_train, n_val]) # バッチサイズの定義 batch_size = 256 # Data Loader を定義 train_loader = torch.utils.data.DataLoader(train, batch_size, shuffle=True, drop_last=True, num_workers=4) val_loader = torch.utils.data.DataLoader(val, batch_size, num_workers=4) test_loader = torch.utils.data.DataLoader(test, batch_size)
では、変換後のデータを可視化してみましょう!
# 学習データの先頭 100 サンプルを確認 plt.figure(figsize=(10, 10)) for n in range(16): x, t = train[n] plt.subplot(4, 4, n+1) plt.title(train_val.classes[train[n][1]]) plt.axis('off') plt.imshow(x.permute(1, 2, 0))

すると、このようなデータが出てきました。変換前のデータと見比べてみましょう。
【参考】変換前のデータ

見比べると定義した変換(左右反転、中央の切り抜きなど)が行われている事がわかります。
では、この変換後の画像データセットを用いて、モデルを学習してみましょう!
モデルの構築
今回は、デモのため簡単な CNN ( 畳み込み層 * 2層 + 出力層 * 1 層 ) を構築し、学習してみます。
ご自身のモデルに適用する場合も、基本的に手順は同じですのでご安心ください。
では早速モデルを用意します。
# 評価指標の設定 from torchmetrics.classification import MulticlassAccuracy accuracy = MulticlassAccuracy(num_classes=10).to(device='cuda') # モデルの設計 class CnnClassifier(pl.LightningModule): def __init__(self): super().__init__() self.conv1 = nn.Conv2d(in_channels=3, out_channels=32, kernel_size=3, padding=1) self.bn1 = nn.BatchNorm2d(32) self.conv2 = nn.Conv2d(in_channels=32, out_channels=64, kernel_size=3, padding=1) self.bn2 = nn.BatchNorm2d(64) self.fc = nn.Linear(64*8*8, 10) def forward(self, x): h = self.conv1(x) h = F.relu(h) h = self.bn1(h) h = F.max_pool2d(h, kernel_size=2, stride=2) h = self.conv2(h) h = F.relu(h) h = self.bn2(h) h = F.max_pool2d(h, kernel_size=2, stride=2) h = h.view(-1, 64*8*8) h = self.fc(h) return h def training_step(self, batch, batch_idx): x, t = batch y = self(x) loss = F.cross_entropy(y, t) self.log('train_loss', loss, on_step=True, on_epoch=True, prog_bar=True) self.log('train_acc', accuracy(y, t), on_step=True, on_epoch=True, prog_bar=True) return loss def validation_step(self, batch, batch_idx): x, t = batch y = self(x) loss = F.cross_entropy(y, t) self.log('val_loss', loss, on_step=False, on_epoch=True) self.log('val_acc', accuracy(y, t), on_step=False, on_epoch=True) return loss def test_step(self, batch, batch_idx): x, t = batch y = self(x) loss = F.cross_entropy(y, t) self.log('test_loss', loss, on_step=False, on_epoch=True) self.log('test_acc', accuracy(y, t), on_step=False, on_epoch=True) return loss def configure_optimizers(self): optimizer = torch.optim.Adam(self.parameters(), lr=0.01) return optimizer
学習してみる
では、このモデルを学習してみましょう!
train_loader , test_loader にはすでに変換後のデータセットが入っています。
今回は、GPU を使って 20 回学習します。 Google Colab での実行時間は 7分ほどです。
# 学習の実行 net = CnnClassifier() # 定義したモデルの呼び出し trainer = pl.Trainer(max_epochs=20, accelerator='gpu') # 学習方法の設定 trainer.fit(net, train_loader, val_loader) # モデルを学習
これで学習が完了しました!では、テストデータでテストしてみましょう!
テストしてみる
# テストデータで検証 results = trainer.test(dataloaders=test_loader) results
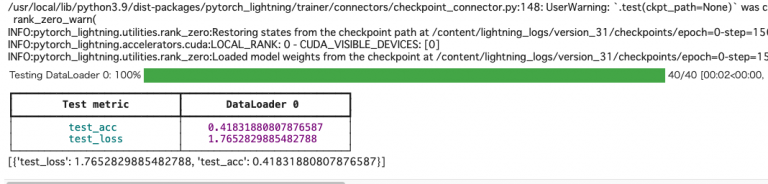
さて結果は、認識精度は ... ?
test_acc = 42% 程度と心もとないですね。流石にモデルが簡単すぎ & 学習が短すぎたようです!
今回は実行時間とわかりやすさのために、簡単なモデルで実装しています。
ただし、モデルをしっかり設計し、学習回数を確保すると、確実に性能は伸びてきますので、是非トライしてみてください!
まとめ
いかがでしたでしょうか?
データ拡張は、意外と簡単に実装できることが伝わったかと思います!
あらためて、データ拡張の手順はこちらでした!
データ拡張の手順
- データセットの変換内容の定義
- 変換内容に基づいて、データセットを変換&取得
以上の手順をおさえて、皆さんもデータ拡張の実装に取り組んでみてください!
本ブログは以上となります。ありがとうございました!\(^o^)/
最速で学びたい方:キカガクの長期コースがおすすめ
.jpg&w=3840&q=75)
キカガクの長期コースはプログラミング経験ゼロの初学者が最先端技術を使いこなすAIエンジニアになるためのサポート体制が整っています!
実際に未経験からの転職・キャリアアップに続々と成功中です
まずは無料説明会で、キカガクのサポート体制を確認しにきてください!
説明会ではこんなことをお話します!
- 国も企業も育成に力を入れている先端 IT 人材とは
- キカガクの研修実績
- 長期コースでの学び方、できるようになること
- 料金・給付金について
- 質疑応答
まずは無料で学びたい方: Python&機械学習入門コースがおすすめこちら
.png&w=3840&q=75)
AI・機械学習を学び始めるならまずはここから!経産省の Web サイトでも紹介されているわかりやすいと評判の Python&機械学習入門コースが無料で受けられます!
さらにステップアップした脱ブラックボックスコースや、IT パスポートをはじめとした資格取得を目指すコースもなんと無料です!
SHARE
新着記事
.png%3Fw%3D1086&w=3840&q=75)
.png%3Fw%3D1086&w=3840&q=75)
.png%3Fw%3D1086&w=3840&q=75)
関連記事



キカガクラーニング
AI/データサイエンス学びはじめの方におすすめの記事



.png%3Fw%3D1070&w=3840&q=75)
コース一覧

注目記事

.png%3Fw%3D200&w=3840&q=75)
.png%3Fw%3D200&w=3840&q=75)

新着記事
.png%3Fw%3D200&w=3840&q=75)
.png%3Fw%3D200&w=3840&q=75)
.png%3Fw%3D200&w=3840&q=75)

