ChatGPT の基礎技術!GPT-3 と Few-shot learning

こんにちは!キカガク機械学習講師の船蔵です!この記事では、ChatGPT の基盤技術としても知られている GPT-3 について解説します。
本記事はこんな方にオススメです
- GPT-3 の概要を掴みたい
- Few-shot larning とファインチューニングの違いを知りたい
目次
ChatGPT
ChatGPT は OpenAI が作成したチャットボットです。何か話しかけると、次の例のように雑談相手になってくれます。

ChatGPT が注目されているのは、その守備範囲の広さゆえです。問いかけの仕方次第で、翻訳・プログラミング・文書校正など広範なタスクをこなすことができます。個人的には、自分の書いているプログラムがうまく動かない時によく助けてもらっています。
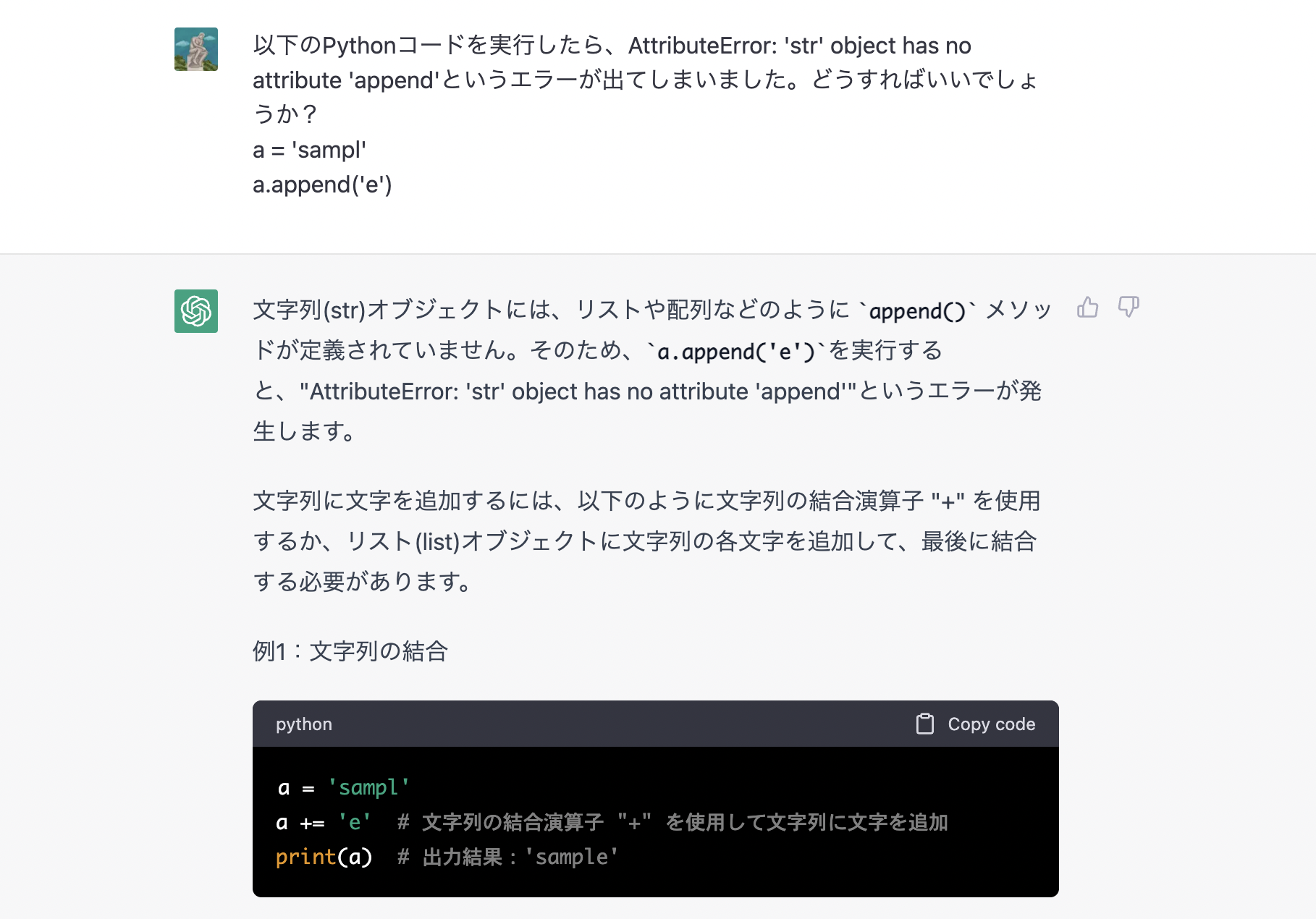
また、文脈を考慮した推論(ざっくり言えば「空気を読む」こと)は自然言語処理システムにとって難易度が高い分野とされています。試しに次のように尋ねてみました。ChatGPT からの返答はとても自然なものに思えます。

ここでの例に限らず、ChatGPT は極めて多様に活用できるでしょう。また、ChatGPT の API が公開されたことで、ChatGPT を活用したアプリケーションも続々と登場しています。
ChatGPT 以後の展開
- 機械学習系の国際会議である ICML は ChatGPT などの言語モデルで生成した文章の論文内での使用を禁止するアナウンスを出しています。また、言語処理学会の 2023 年次大会では ChatGPT の登場を受けて緊急企画が組まれるなど、学術界にも影響を与えています。
- ChatGPT に続いてウェブ検索ベースの The new Bing が公開されました。
GPT-3
GPT-3 は、ChatGPT の基礎をなす機械学習モデルです。従来のモデルと比べて幾つかの点で革新的であり、GPT-3 の出現はその後の機械学習界に大きな影響をもたらしました。
本記事は、GPT-3 のさまざまな特筆点の中でも特に Few-shot learning と呼ばれる学習方策に注目して、関連する基礎知識と、その後への影響について解説します。
補足
GPT-3 は Brown et al. 2020. Language models are Few-shot learners という論文で提案されました。
GPT-3の特長まとめ
GPT-3が卓越している点は大きく次の三点です。
- 学習データ量
- パラメータ数
- 学習方策
本記事で注目するのは三点目の学習方策ですが、学習データ量とパラメータ数についても概観しておきましょう。
学習データ量
GPT-3 は Common Crawl dataset を中心としたテキストコーパスを用いて学習しています。学習に使われたデータセットは約 5000 億トークンからなり、学習データとしての質を保つために幾つかのフィルタリングが施されています。
パラメータ数
GPT-3 のパラメータ数は、最も多いモデルで 1750 億です(提案論文ではパラメータ数の設定をいくつか試しています)。前身の GPT-2 のパラメータ数が 15 億なので、100 倍以上のパラメータを持っていることになります。
以上の二点から、GPT-3 は学習データ、パラメータ共に膨大であることがわかります。モデルをスケールアップするほど性能が向上するということはそれ以前から示唆されていましたが、GPT-3 はその予想を経験的に支持するものと言えるでしょう。
学習方策
もう一つの特筆点は、GPT-3 の採用する学習方策です。GPT-3 は、具体的なタスクに特化したパラメータ更新を行わずにさまざまなタスクを解決します。これを実現する方策として GPT-3 は Few-shot learning という方法を採用しています。
タスクごとにパラメータ更新を行わないというアイデア自体は GPT-3 以前から提案されていましたが、GPT-3 はこのアイデアを基にして、ファインチューニングに匹敵する性能を示した点で大きな注目を集めました。次節以降では Few-shot learning に関連する基礎知識と、GPT-3 登場後の展開について解説します。
補足
- GPT-3 論文では学習方策として Zero-shot leaning と One-shot leaning も検討していますが、本記事では割愛します。
- Few/One/Zero-shot learning という用語の伝統的な意味合いには、パラメータ更新をせず学習することが必ずしも含まれるわけではありません。一方で GPT-3 における Few/One/Zero-shot learning は、パラメータ更新をせずに少数のデータから学習することを意味しています。
Few-shot learning
Few-shot learning の利点を理解する上で、ファインチューニングとの対比はとても重要です。まずはファインチューニングについて簡単に解説します。
ファインチューニング
ファインチューニングとは、タスクに対するモデルの初期値として、別のタスクによって事前に調整されたものを用いる手法です。あらかじめ行う学習を事前学習 (pre-training) と呼び、事前学習されたモデルを別のタスクのために微調整することをファインチューニング (fine-tuning) と呼びます。
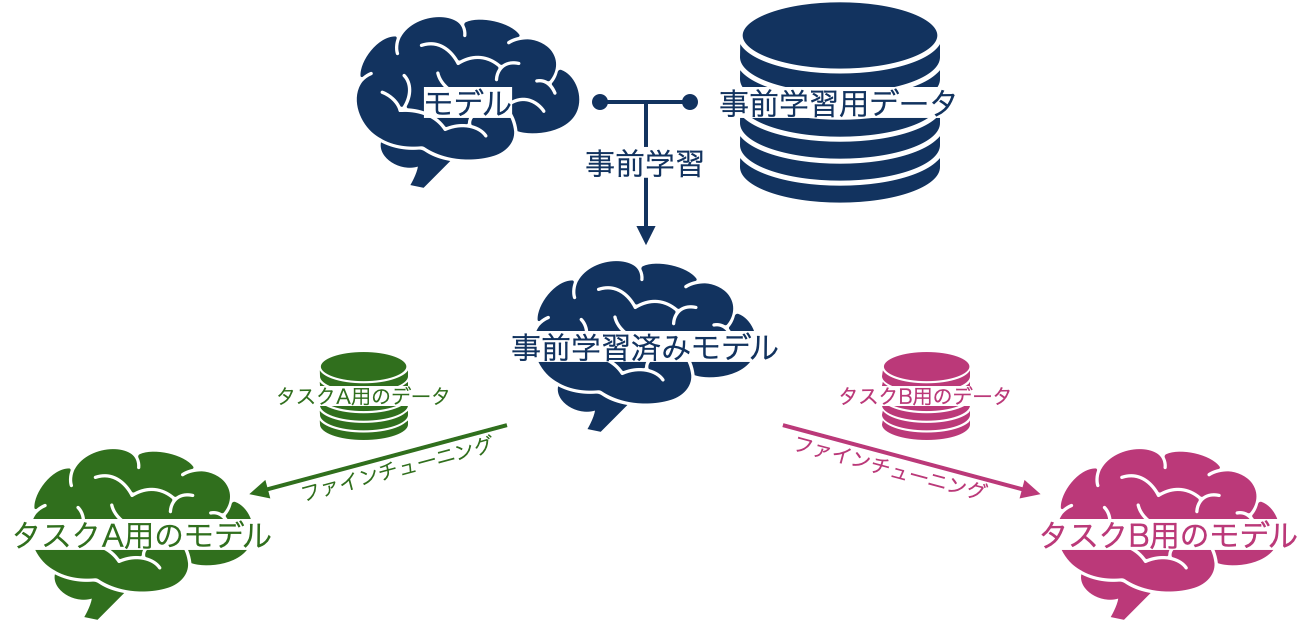
事前学習時のタスクとして典型的なのは言語モデリング、つまり、単語列を入力として、次に現れる単語を予測するタスクです。

事前学習されたモデルを翻訳や対話など別のタスクに合うよう微調整することで、良い性能が得られるということが経験的に明らかになっています。ここでいう翻訳や対話のように、微調整によって解こうとしているタスクのことを下流タスク (downstream task) と呼びます。
ファインチューニングの利点は、下流タスクのためのデータが比較的少なく済むことです。深層学習モデルの学習のためには大規模なデータが必要ですが、事前学習されたモデルのパラメータを初期値とすることで、比較的少ないデータで良い性能を出すことができます。
一方で、GPT-3 で採用されている Few-shot learning には、ファインチューニングに相当する手続きが含まれません。つまり GPT-3 は、個別のタスクに特化したパラメータ更新を行うことなく、各タスクを解くことを目指しているのです。
プロンプト
GPT-3 はプロンプト (prompt)と呼ばれる文字列を入力として文字列を出力するモデルです。

プロンプトにはモデルに解かせたいタスクの種類や、簡単なデモンストレーションを記述します。OpenAI のウェブサイトで GPT-3 を試すことができるので、実際にプロンプトを打ち込んでみましょう。
はじめに翻訳を試してみましょう。次のようなプロンプトを入力として与えます。
一行目には「英語から日本語に翻訳せよ」と書かれており、その下にいくつかの例題とその答えが提示されています。最後の行の cheese => は正解部分が空欄になっており、モデルはこの部分を予測します。
結果として、cheese に対して「チーズ」という予測が返ってきます。
今の例では翻訳問題を解かせましたが、同じモデルに質問応答を行わせてみます。質問応答の問題を解かせるために、次のプロンプトを入力します。
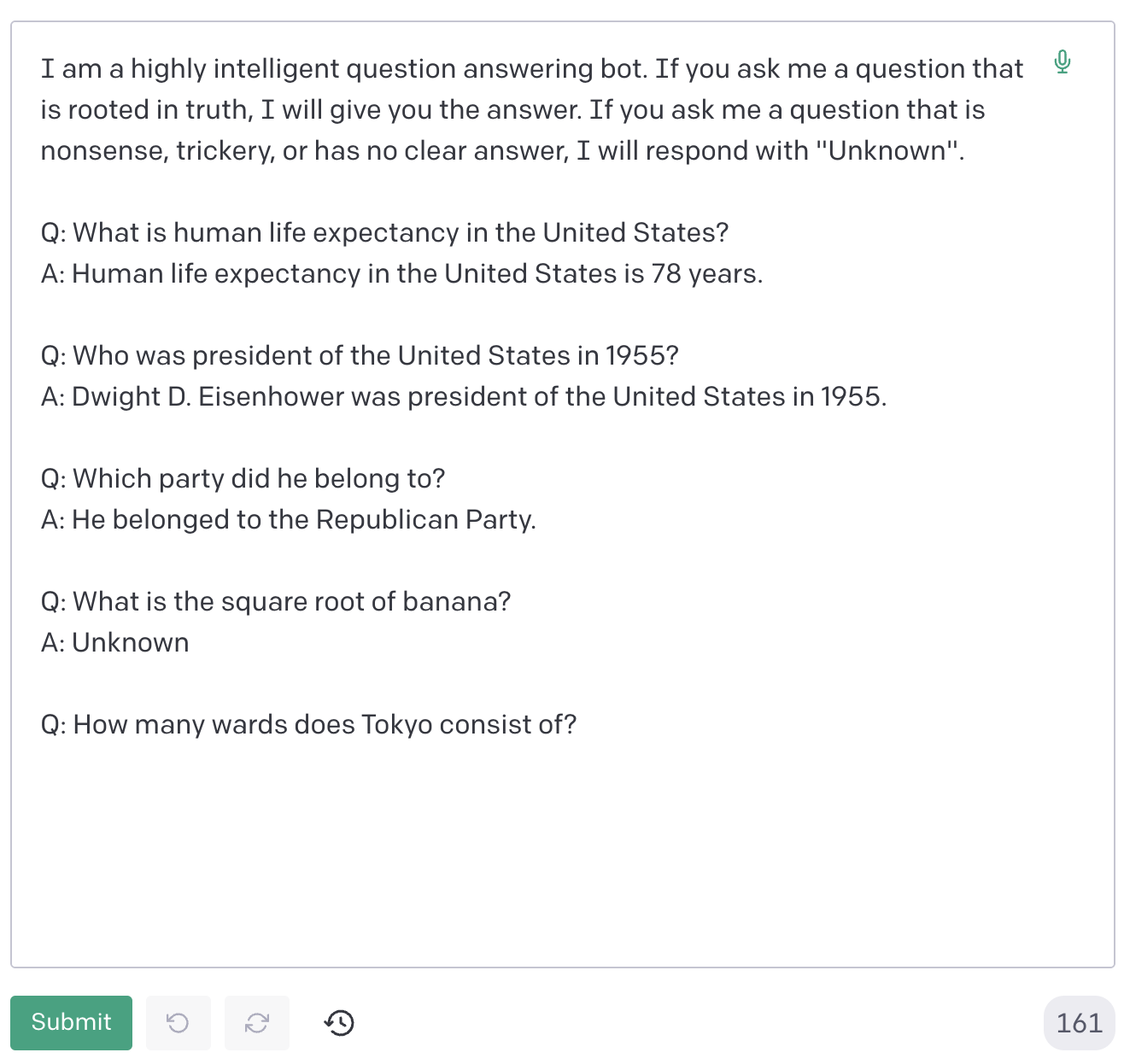
はじめに質問応答をせよという旨の文章を与え、次にいくつかの例題とそれに対する回答を提示しています。最後に、”How many wards does Tokyo consist of?” (東京はいくつの区からなる?) と問いかけ、答えを空欄にしておきます。すると次のように回答が出力されます。
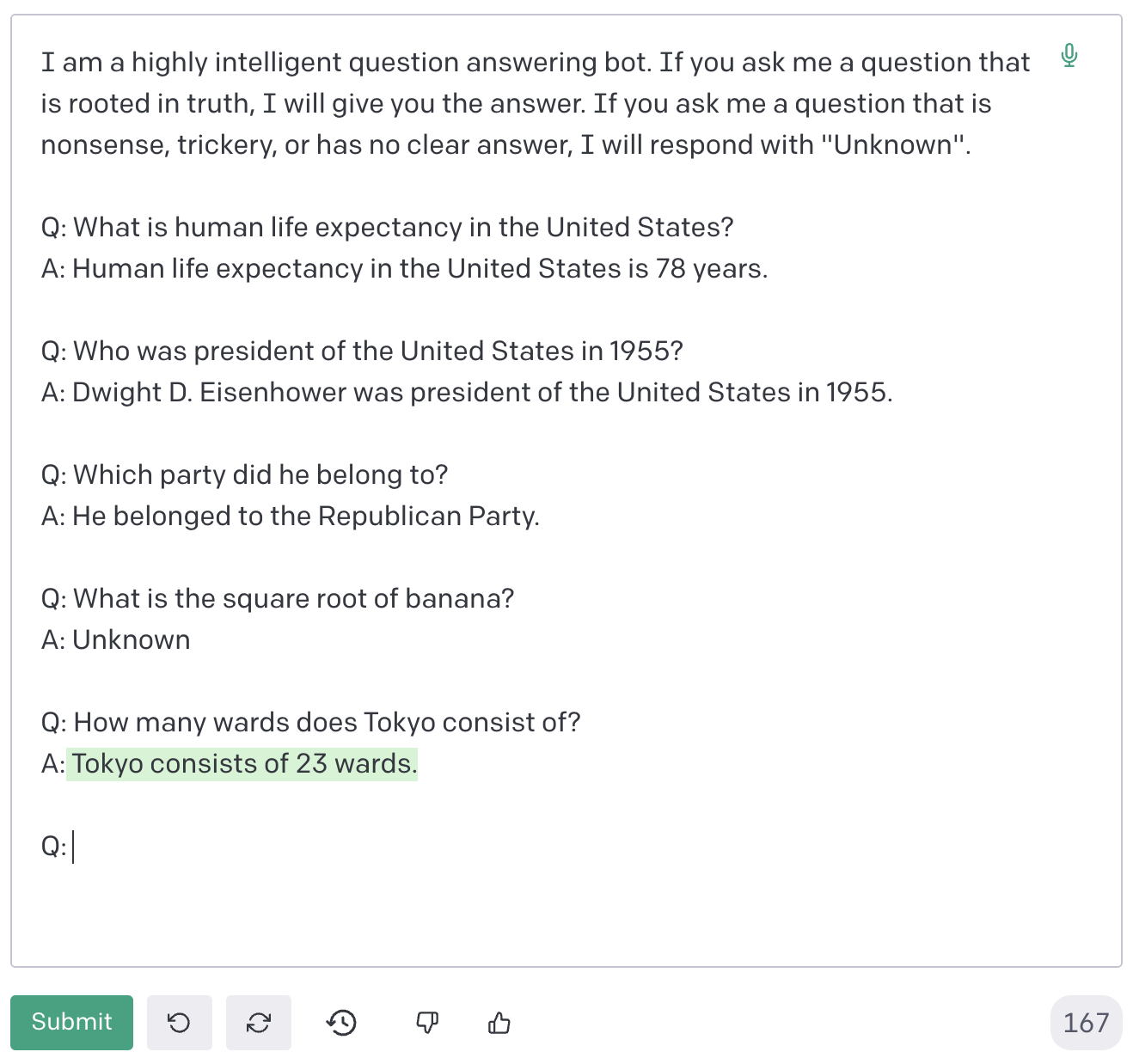
”Tokyo consists of 23 wards.” (東京は23区からなる) と返ってきました。
このように、GPT-3 はプロンプトの与え方次第でさまざまな問題を解くことができます。ただし、言語モデルの出力が必ずしも正しいわけではないということに注意する必要があります。
同様のプロンプトで、質問を "Who is the female prime minister of Japan?" (日本の女性首相は誰?) に変えてみます。今のところ日本に女性首相は居ないので、望ましい答えは "Unknown" ないしは "There is no female prime minister in Japan." (日本に女性首相は居ない) などが考えられます。
しかし、モデルから返ってきたのは次の回答です。

「日本の女性首相は Yoshihide Suga です」と返ってきました。この例から分かることは、モデルからの返答が事実に基づくものであるとは限らないということです。これは GPT-3 固有の問題ではなく、言語モデルに共通の性質であるといえます。言語モデルが、コーパスをもとに学習して確率的に文章を生成するという方針をとっている以上、十分あり得ることとして理解するべきかもしれません。
上述のような言語モデルの特性を背景として、言語モデルからの出力結果の信頼性を検証するシステム Critique が Inspired Cognition から公開されました。このようなツールは、特に言語モデルを活用したプロダクトを提供する上でとても重要だと思われます。
ファインチューニングと Few-shot learningの違い
ここまでの内容を振り返りつつ、ファインチューニングと Few-shot learning の違いについて解説します。ここでは以下の二点に注目します。
- コストの所在が異なる
- 試行錯誤の対象が異なる
コストの所在が異なる
ファインチューニングで複数のタスクを解くためには、タスクごとにモデルのコピーを作り、パラメータ更新を行う必要があります。
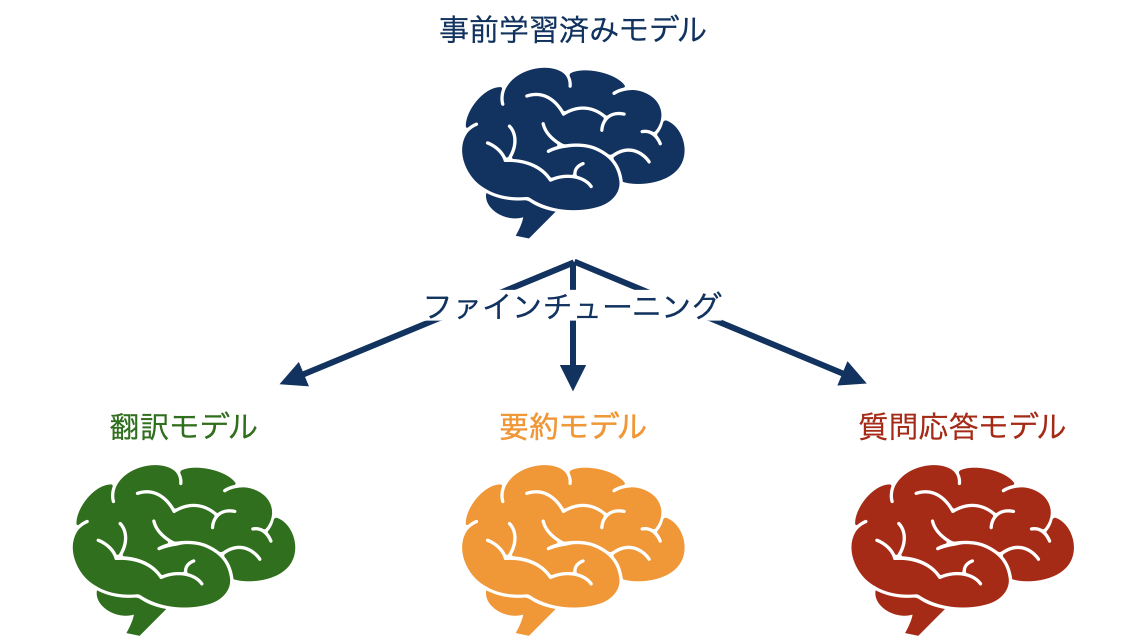
ファインチューニングの特徴は、個別タスクへの適用のために必要なデータが比較的少なくて済むという点にあります。ただし、望ましい性能のためには数万サンプル以上必要になる場合が多いでしょう。
一方で、GPT-3 の採用する Few-shot learning は、取り組むタスクをプロンプトによって制御する手法です。この手法は、タスクを通じて共通のモデルを使用します。
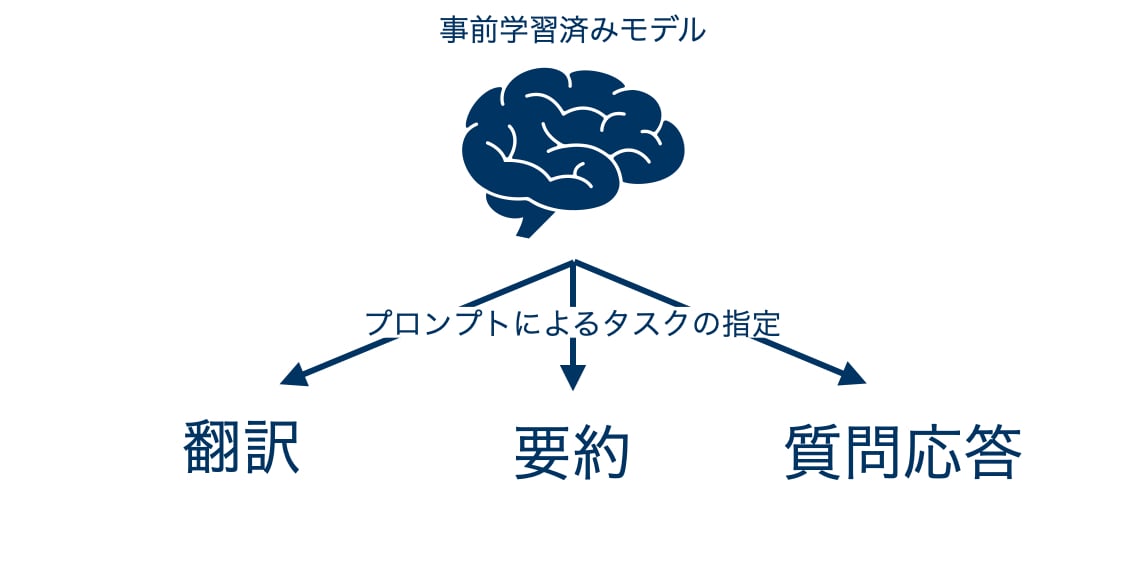
したがって、ファインチューニングの場合に必要となるモデルの複製・タスクごとの学習のためのコストが Few-shot learning では不要となります。つまり、Few-shot learning は下流タスクに適応するコストが削減されていると言えます。
とはいえ、GPT-3 は事前学習のために莫大なデータを使用しており、さらにモデルも巨大です。そのため、単にコストカットができたというより、コストの比重が事前学習に置かれていると見ることもできるでしょう。
試行錯誤の対象が異なる
ファインチューニングで良い性能を達成するためには、良い事前学習モデルと、ファインチューニングのための高品質な学習データが少なくとも必要になります。
これに対して、Few-shot learning で良い性能を達成するには、良い事前学習モデルと、良いプロンプトが必要です。プロンプトの長さには限りがあり、タスクの特性を的確に捉えた、簡潔なプロンプトを考案する必要があります。
しかし、どのようなプロンプトにすれば良い性能が得られるかは自明ではなく、試行錯誤が必要です。良いプロンプトのための試行錯誤はプロンプトデザイン (prompt design) と呼ばれています。
プロンプトデザインについては、OpenAI の技術ディレクターによる解説動画で詳しく知ることができます。また、Prompt Engineering Guide には、プロンプトに関する膨大な情報がまとめられています。
本章のまとめ
この章では、ファインチューニングに基づく課題解決と、プロンプトに基づく課題解決について解説しました。要点をまとめます。
- Few-shot learning はプロンプトによって下流タスクに適応する
- プロンプトによる適応はパラメータ更新を必要としない
- ファインチューニングと Few-shot learning は、コストの所在、試行錯誤の対象が異なる
その後の展開
この章では GPT-3 以後の動向について、プロンプトを学習するモデルの研究に焦点を当ててご紹介します。
Few-shot leaning が注目を集めたことで、「良いプロンプトの作り方」を追求する研究が増えてきました。その例としてプロンプトを学習対象とする研究が挙げられます。
プロンプトを人手で考えるのはコストがかかる作業であることや、どうすれば効果的なプロンプトになるかが自明ではないといったことがこのような研究を動機づけています。
プロンプトの学習に関する主な文献を次に提示します。
- Shin et al. (2020) Autoprompt: Eliciting knowledge from language models with automatically generated prompts
- Li et al. (2021) Prefix-tuning: Optimizing continuous prompts for generation
- Lester et al. (2021) The power of scale for parameter-efficient prompt tuning
おわりに
本記事では、Few-shot leaning と GPT-3 以後の展開について解説しました。重要ポイントをまとめます。
- Few-shot leaning は少数の学習データによって下流タスクに適応する手法である
- ファインチューニングと異なり、Few-shot leaning は勾配計算・パラメータ更新を行わない
- プロンプトを人手で模索するのではなく、学習により最適化する研究が勢いを増している
Few-shot learning はファインチューニングの対抗馬として強調されがちですが、むしろ相補的な特長を持つ手法と言うべきかもしれません。
GPT-3 + Few-shot learning でファインチューニングに匹敵するには、巨大なモデルと事前学習データが必要です。また、適切なプロンプトを簡単に作れるわけではありません。こういったことを踏まえて、場面に応じて良い手法を模索するのが現状の最適解だと私は思っています。
この記事では学習方策に注目していましたが、GPT-3 の中核をなす Transformer、さらに Transformer を支える注意機構なども掘り下げるととても面白いです。また、画像や音声などの他領域で Few-shot learning がどう活用されているかも興味深いです。これらの話題も今後の記事で扱っていきたいと思います!
参照文献リスト
- Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J. D., Dhariwal, P., … & Amodei, D. (2020). Language models are Few-shot learners. Advances in neural information processing systems, 33, 1877-1901.
- Shin, T., Razeghi, Y., Logan IV, R. L., Wallace, E., & Singh, S. (2020). Autoprompt: Eliciting knowledge from language models with automatically generated prompts. arXiv preprint arXiv:2010.15980.
- Li, X. L., & Liang, P. (2021). Prefix-tuning: Optimizing continuous prompts for generation. arXiv preprint arXiv:2101.00190.
- Lester, B., Al-Rfou, R., & Constant, N. (2021). The power of scale for parameter-efficient prompt tuning. arXiv preprint arXiv:2104.08691.
最速で学びたい方:キカガクの長期コースがおすすめ
.jpg&w=3840&q=75)
キカガクの長期コースはプログラミング経験ゼロの初学者が最先端技術を使いこなすAIエンジニアになるためのサポート体制が整っています!
実際に未経験からの転職・キャリアアップに続々と成功中です
まずは無料説明会で、キカガクのサポート体制を確認しにきてください!
説明会ではこんなことをお話します!
- 国も企業も育成に力を入れている先端 IT 人材とは
- キカガクの研修実績
- 長期コースでの学び方、できるようになること
- 料金・給付金について
- 質疑応答
まずは無料で学びたい方: Python&機械学習入門コースがおすすめこちら
.png&w=3840&q=75)
AI・機械学習を学び始めるならまずはここから!経産省の Web サイトでも紹介されているわかりやすいと評判の Python&機械学習入門コースが無料で受けられます!
さらにステップアップした脱ブラックボックスコースや、IT パスポートをはじめとした資格取得を目指すコースもなんと無料です!
SHARE
新着記事
.png%3Fw%3D1086&w=3840&q=75)

.png%3Fw%3D1086&w=3840&q=75)
関連記事



キカガクラーニング
AI/データサイエンス学びはじめの方におすすめの記事



.png%3Fw%3D1070&w=3840&q=75)
コース一覧

注目記事

.png%3Fw%3D200&w=3840&q=75)
.png%3Fw%3D200&w=3840&q=75)

新着記事
.png%3Fw%3D200&w=3840&q=75)

.png%3Fw%3D200&w=3840&q=75)
.png%3Fw%3D200&w=3840&q=75)
.png%3Fw%3D200&w=3840&q=75)